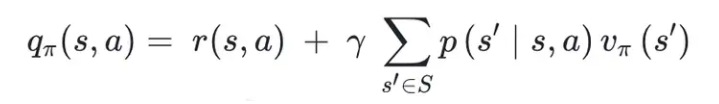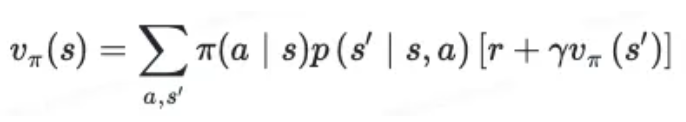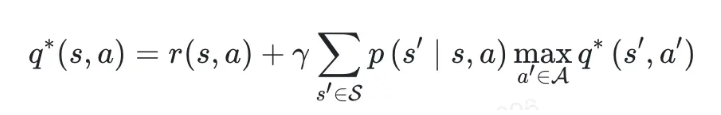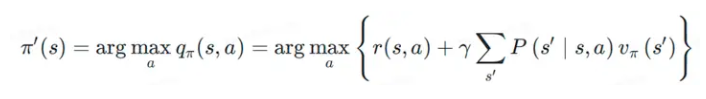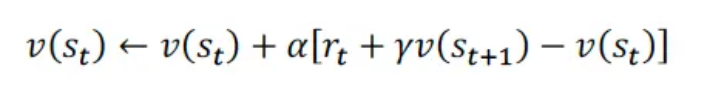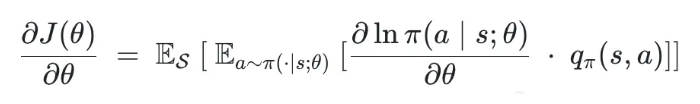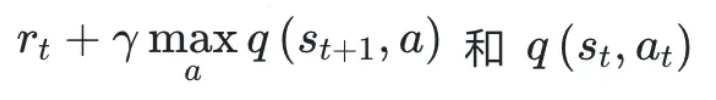天池大赛:不确定竞价 —— 赛题解读(2)
广告竞价模型。同类的几篇文章,不知对伙伴们是否有作用?
01 关于 Copula 函数
参考文章
Copula函数——一种处理变量之间相关性的统计学工具 Copula系列(一)-什么是Copula函数 朗读 + 讲解
02 知乎:强化学习入门:基本思想和经典算法
参考文章
知乎高赞文章:《
强化学习入门:基本思想和经典算法 》
这篇文章需要多打点基础,再来看的时候,可能有豁然开朗的感觉。基础一般的,跳到本篇的 【03】 部分,直接阅读,或者听取本站的朗读讲解内容,全线真人声音!
几天之后,我们发现传统的方法似乎解决不了这个问题,还是 Refer to 增强学习吧!
识别一种模式,训练这种模式,找到执行者(Agent),建立经验库,最终和环境交互。
还有一点就是,其实也没特别理解,理解程度 50% 吧。今天压力太大,我要干点正事儿去了!这些工作非常前瞻,非常重要,非常难。可是不能忘了生存问题呀。
1.智能体,以及 Re-inforcement Learning 基本图示
(1)如果狗执行了我们的指令(action),我们就给予骨头等奖励(reward)
(2)如果狗不执行我们的指令(action),我们就给予一些惩罚(负向的reward)
(3)通过一定时间的强化(反复)训练,狗就学会了对指令的执行
关于迭代算法的伪代码。这里注意价值函数 Q 是如何迭代的?
下图这个算法,有个点有点疑问。即 第七行 有以下特点:
右边 = Q + alpha*[ r + gamma*max(Q_s1) - Q_s ]
其中,Q_s 含义为对 Q 的估计;
max(Q_s1) 是真是发生的 Q 的值。
鉴于算法是有罗列之后,选择使得价值最优化的做法。因此,每个面板上作出模型之后,最优化的策略/行动,为真实发生的;同时,期望 策略/行动 即估计。
2.关于 增强学习 分支树
本篇和之后的文章,更多讨论 Model-Free 的情况,还区分 Policy Optimization 和 Q-Learning。
3.基于价值 Value-Based v.s. 基于策略 Policy-Based
基于价值和基于策略的解释,后篇也有提到,可能不太对,我这里留个疑问。
朗读 + 讲解
《
强化学习入门:基本思想和经典算法 》
03 知乎:终于有篇文章把强化学习的原理彻底讲透了!
参考文章
知乎高赞文《
终于有篇文章把强化学习的原理彻底讲透了! 》
(1)马尔科夫性质
简言之:今天某个变量的取值,只与昨天有关,与昨天之前无关。或者基于昨天的,和基于前一礼拜的,概率一致。公式如下:
(2)策略 Policy
首要明确,策略输出的是一个概率,没有单位的概率。
(3)价值函数 Q_pi
简言之,价值函数 Q_pi 是环境的回报,和对未来设想的期望的,加权平均。
最基础表达式,必须记住!
(4)贝尔曼方程 Bellman Equation
简言之,在对未来价值期望的基础上,乘以行动所采取的概率。
最有价值函数的 Bellman EQ
注意到 Bellman Equation 表达式,涉及时序差分。
(5)策略迭代 Policy Iteration
文章中说到的 s 指的是当前时刻的状态,而 s' 一种选择,即一系列可能的 PATH 中,智能体作出的选择 s'。
针对这个问题,刻画【状态价值函数】:
贪心策略,贪心的地方在于,你所能想到的未来【情况】,每个【情况】都需要计算汇报。贪心算法用公式表达如下:
上述公式中,右边第一项,环境给出的 Reward;右边第二项,系数乘以,对未来预期【情况】的期望。
(6)价值迭代 Value Iteration
最优策略,这样表示:
注意到这个表达式,和贪心策略的表达式几乎一致。
(7)策略迭代 Policy Iteration v.s. 价值迭代 Value Iteration
策略迭代:随机策略开始、算法相对复杂、收敛快。
价值迭代:随机状态价值函数开始,算法相对简单,收敛慢一些。
(8)时序差分法
属于 Model-free 的。
(9)策略梯度
连续方法。根据策略梯度定理(的不严谨的表述),该梯度可如下计算:
这个公式不算特别懂,暂时留个疑问。
在不对价值函数进行建模的情况下,状态-动作-价值函数 qπ(s, )可通过蒙特卡洛近似完成,即:完成一幕(episode)探索,基于所有单步回报,计算出该幕中每一步的累计回报,并用该幕的累计回报来近似近似状态-动作-价值函数。这样的方法被称之为 REINFORCE。
策略梯度定理的推导过程中假设策略网络的参数为实时更新的参数,因此基于策略梯度定理的本节介绍的方法属于同轨策略(on-policy),即:用于完成探索的行为策略(behavior policy),和进行参数优化的目标策略(target policy),是相同参数的网络。同策略无法使用离线收集的数据,而与之相对的离轨策略(off-policy)则可以。
关于策略梯度【学习框架】
(10)经典 RL:Q-Learning 查表法
(11)Sarsa 算法
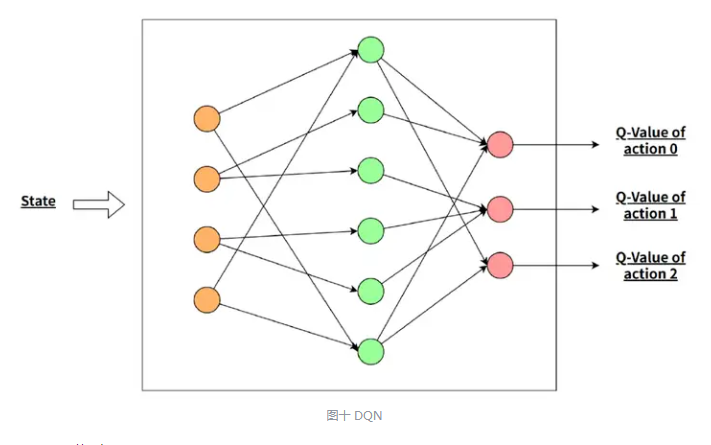
第一,用神经网络,进行 State 输入,到 Value upon action 是输出。
第二,Q-Learning 更新规则:
第三,目标是,使得以下两个值靠得足够近。
朗读 + 讲解
前 13 分钟分享了一下 10 月长假的灵感,小见解。14分钟开始主要内容。
04 Self-Play强化学习最新综述
参考文章
机器之心:
Self-Play强化学习最新综述
原文地址:
A Survey on Self-play Methods in Reinforcement Learning
这个十一黄金周的工作绩效是 3 篇 RL 相关论文,这是第三篇,虽然会偏离原来的 RL 多一些,但是还是挺有启发性的。
本站(其实是笔者)希望我们的工作对大家有稗益,大家可以留言、可以反馈,也可以捐赠。
1. 基本概念
零和博弈,非零和博弈。
2. 经典囚徒困境
• If one player confesses (C) and the other lies (L), the confessor will serve 1 year in jail, while the liar will serve 8 years.
• If both players choose to confess, they will each serve 7 years behind bars.
• If both players choose to lie, they will each serve only 2 years behind bars.
3. 完美信息
定义:一次只有一个玩家可以操作。
Perfect Information: Only one player moves at a time
4. 非完整信息
定义:博弈双方并不知道对方的操作和获益。否则,为完整信息。
Incomplete information: There exists at least one player who is unaware of the payoff of another player
综上,完整信息和完美信息博弈的案例,围棋。
5. Normal-form
博弈标准形式,只有一个回合。可用矩阵显示价值分布。
类似的概念,还有 Static Game / Stage Game。
6. Extensive-form
一系列策略组合成博弈模型。
类似的概念,还有 Dynamic Game / Repeated Game。
7. Transitive Game
三个策略,如果前两个策略为正,剩下一个策略仍然为正,说明 Transitive。即 负面效应可以转移。否则为 Non-transitive Game。
8. Non-transitive Game
三个策略,如果前两个策略为正,剩下策略为负,说明 Non-transitive。
9. Nash Equilibrium
任何一个参与者单边改变其策略,都不能获得更多收益。
朗读 + 讲解
前面 1-2 个Audio 是机器之心文章的朗读,几乎原汁原味,很多我不懂的地方,也做了标记。之后几个 Episode 都是原版论文,写得蛮清楚的,推荐。2024年的文章,关于博弈论的使用,分为:棋类、牌类、游戏类。
2024 年 10 月 6 日 讲解
这个 1 小时的音频全线讲解维纳过程,讲得很清晰了。
机器之心,关于维纳过程定义。
点击了解 。
维纳过程 2023 年 12 月 发布。
点击了解 。
剩下了一些知识点。知识点比较多,暂时就朗读这么些。未来有机会再增加吧!!
04 Self-Play强化学习最新综述
参考文章
一文看懂什么是强化学习?(基本概念+应用场景+主流算法+案例)
下午的时候,新增一篇文章。这篇文章的稗益在于,一些新的理解 RL 的角度。
1. 马尔可夫决策过程可以根据是否使用环境模型分为基于模型和无模型两类。基于模型的算法可以通过学习环境的认知建模,利用状态转移函数和奖励函数来做出最优决策,如使用 MuZero 和蒙特卡洛搜索等算法。无模型算法可以分为基于价值和基于策略两类强化学习算法。
2. 这里介绍几类算法,都是属于 MDP 范畴的。
如使用 MuZero 和蒙特卡洛搜索等算法。无模型算法可以分为基于价值和基于策略两类强化学习算法。
基于价值的强化学习算法仅学习一个价值函数,即估计当前状态下采取动作后的 Q 值,代表性的算法有 DQN。DQN 进一步演化出了 C51 等算法,适用于离散空间,并扩展到连续空间的 DDPG 算法。DDPG 算法采用近似最大化,并衍生出了解决连续空间决策问题的 TD3、SAC 等算法。
在基于策略的强化学习算法中,可以分为无梯度和有梯度两类。无梯度算法采用进化策略等演化计算类似的算法。有梯度算法则包括 TRPO 算法、PPO 算法等,其中PPO 算法在 MOBA 游戏 AI 和大语言模型的 RLHF 训练中得到了广泛应用。
3. DQN 算法:在强化学习领域,DQN 算法是一种广受欢迎的经典方法,它基于价值函数进行学习。
DQN 致力于估计在给定状态下执行某个动作的长期回报。为实现这一目标,DQN 利用贝尔曼方程来构建一个目标值,该目标值由当前状态的即时奖励和从下一个状态到序列结束的最大可能价值组成。值得一提的是,DQN 算法在理论上具有一定的收敛性保证。具体来说,当所有的状态-动作对都被无限次地访问,并且学习率满足一定条件时,DQN 可以逐渐收敛到最优的价值函数。
4. 强化学习推荐算法提升短视频留存
留存率直接反映了用户对推荐内容或平台的体验,因此,对于如抖音、快手等平台来说,留存率成为了其核心的评估标准。留存率作为用户与平台多次交互的长期反馈,体现了用户每次打开 APP、观看多个视频后的行为决策。用户可能会在一段时间后重新返回 APP,这种延迟反馈与围棋比赛中的阿尔法 go 类似,需要在多步之后进行评估。
在此场景下,我们将问题建模为一个无穷序列的马尔可夫决策过程,其中每次用户打开 APP 都被视为一个新的开始。
5. 基于无限域请求的马尔可夫决策过程
最终目标是最小化多个会话之间的回访时间间隔。通过这样的建模和优化,我们能够更精确地理解用户行为,并提供更符合其偏好的视频推荐,从而提升用户体验和满意度。
6. 用户留存算法的强化学习
接下来将深入探讨这一方法的训练过程。我们所采用的是一个 active critic 学习框架,其核心在于优化回访时间目标及其与即时信号 critic 值之和。在 critic 的学习过程中,例如对于留存率(retention)这一信号,我们采用了一种基于 TD-learning 的方法,其机制类似于 TD3 方法(
DataFunTalk, 2024 )。
ShoelessCai 评注,笔者在这个问题上,建议先记住算法名字,用到多少学多少。主要是作者也没有解释得非常清晰。
朗读 + 讲解