封面故事:
【腾讯云 HAI域探秘】释放生产力:基于 HAI 打造团队专属的 AI 编程助手
TechoDay 长沙 | 腾讯云无代码产品分享会
2024 年 10 月 25 日,TechoDay 在湖南长沙举行,腾讯会议 14:30 线上直播。
本人进入会议室的时候,已经是下午 3 点,虽然只听到一半,也是对 AI 大模型又有了新的认知。
汪晟杰
针对大模型,目前诉求是做到对现实问题的精准认知。具体步骤:
上传代码 - 进入向量数据库 - 建立索引 - 匹配已有 Chunk - 生成提示词 Prompt
最终,用户就能获得自己在混元大模型得到的答案了。
专业词:召回率。
所谓召回率,其实测试的是知识库的被利用率,可以理解为,知识被使用率。
分享者说到,腾讯云该产品部门的召回率还是很高的,而用户的体验式,提交文档或者代码,获得对应的,符合需求的代码块 Chunk。同时,为了提升用户体验,还能做到支持压缩包等各种其他的体验优化。
这款产品的指标是效率是否提升,交付形式是输出代码。因此,在开发的时候,注重 Agent 能力开发。
关键:对知识如何切分、存储?
腾讯的做法,首先要 Scan 目录,然后找到知识主干,在扫描的时候,做到完整切分。
Prompt、RAG、微调 如何分配?
第一,如果不纠结时间,纠结质量的,可以直接微调;
第二,大多数时候,业务需要短而快地交付,输入代码库、文档,由 RAG 或者 RAG 及微调,进行个性化的调整。
知识库,如何理解?
例如,notebook.im,通常就是使用 Agent + 知识库的模式,知识库是 LLMs 联动的 Data Source。
模型建立的步骤:数据输入 - 训练 - 测评。这里的测评也是有很多工作的。
针对个人/企业用户,如何使用该产品?
第一,个人提升效率,下载腾讯云这款产品代码,微调。团队在开发的关键数据,做了透明化。
第二,企业用户的使用,是角色增加。个人用户不断邀请其他人使用,就形成社群,变成企业效率产品。注意,针对不同企业,可以基于私域做个性化,同时也含有标准化产品。
AI 未来在哪?
第一,团队关注 AI for SE。
AI4SE(Artificial Intelligence for Software Engineering)是指人工智能技术应用于软件工程领域,旨在通过利 用AI 算法和工具来改进软件开发、 维护、测试和管理等各个环节的效率和效果。AI4SE的核心目标是通过自动化和智能化技术,降低软件开发的复杂性,提高软件的质量,并加速软件工程过程(
AI 辅助软件工程:实践与案例解析,2024)。
AI 赋能无代码可以分为两个层面:
第一个层面,“SE for AI”,通过无代码的软件开发降低AI的使用门槛。让所有用户可以基于平台享受到AI的便捷性。
第二个层面则是反过来,“AI for SE”,核心是让无代码的开发过程本身也具备更加智能化的能力。降低过去需要经验丰富的工程师才能做到的软件开发门槛,让业务人员也能更快地用起来(
雪球-数睿数据,2023)。
第二,团队在对话测试得最多,也是现在正在进行的事情。开发的目的是什么呢?无非四大目的:代码效果越来越好;提升效率;降低成本;建立专属知识库。
第三,有助于个人开发、企业研发,生成代码的过程。
第四,AI 未来 10 年占据重要工作,分享者呼吁,无论做什么,都试图和 AI 合作。

闫钰承 HAI 高性能应用
闭源模型:LAMA3、混元大模型等等。
开源模型,为什么使用开源模型? Why Open Source?
1.参数少。例如,LAMA Params 大约只有 7-10 B。
2.针对中国化的业务,其实闭源的模型相对难以修改成适应自己需求的,但是开源的这些适应性就很好。
3.使用大语言模型可能遇到的问题:
(1)要找到模型代码,还有版本、授权等问题;
(2)成本高。例如,很多设备没有英伟达,可能根本无法跑大语言模型;
(3)运维少。例如,缺失数据;
(4)推理效率低,可能由于却数据,或者存储效率等问题。
4.随时都用到 GPU 运算力。
(1)一旦算力形成,团队也是想形成 AI 应用孵化的。
(2)快速部署应用模块,至少部分可以使用;
(3)图形界面;
(4)云存储。
5.如何搭建?
(1)AI 技术环境,例如,LAMA;
(2)AI 框架,例如,TensorFlow、PyTorch;
(3)AI OS,例如,Windows,具体做法,即下载整合包;
(4)可视化交付界面,例如,Notebook、WebUI 等,还有 CloudStudio(没听清楚,应该是部署在腾讯云的云端 IDE)。
(5)成本,例如,应用存档、如何关机(减少浪费)。
6.案例,线上教育。
该客户业务模式是学生在线上上课,遇到问题是学生上课的时间很多变,时间段不统一。腾讯云的解决方法。
这种方法,简言之,通过代码管理体系,客户为几百学生建立生命走起管理档案。
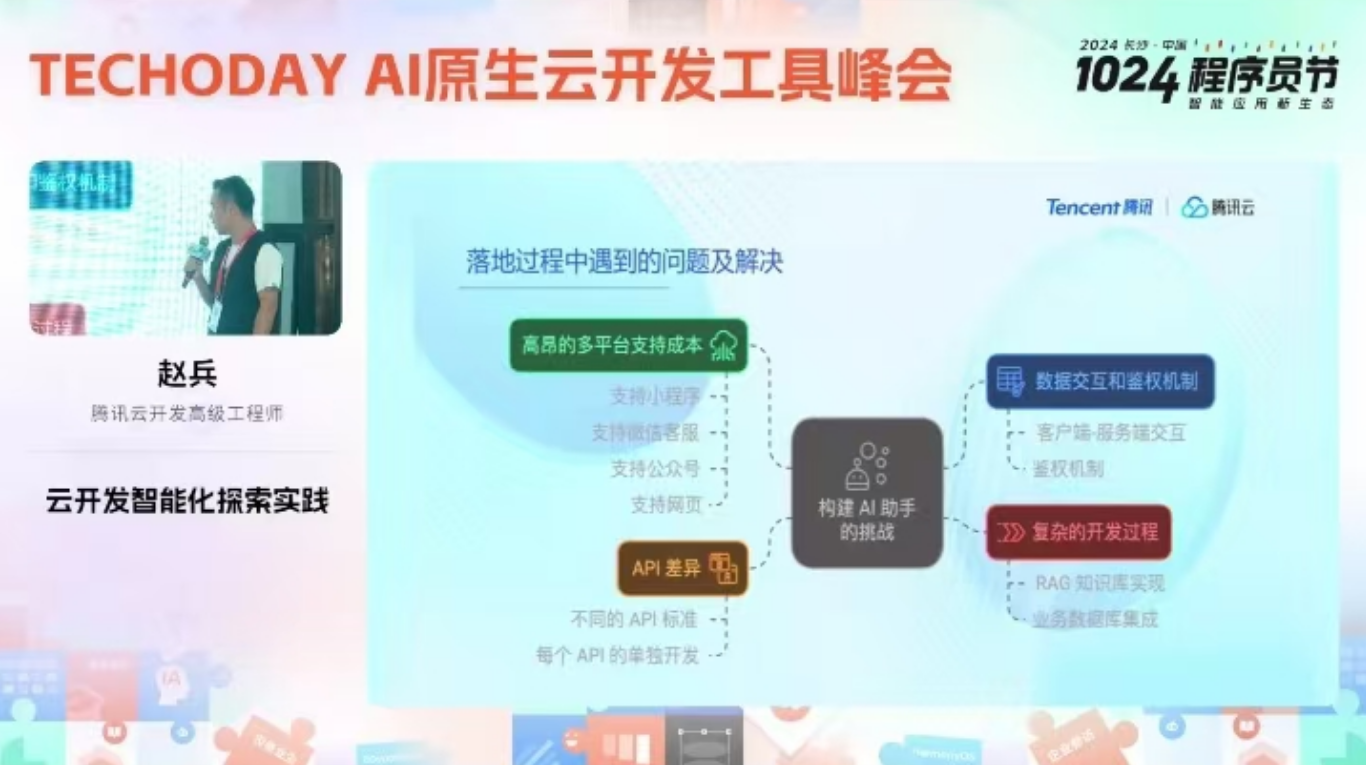
赵兵 云开发
智能化实践,云开发。
1.不买服务器 —— 这里没理解什么意思
2.拖曳式,搭建应用;
3.COT 思维链,用于 拆分项目,拆成不同的业务;
4.RAG 助手。知识库问题:幻觉问题、数据库落后、AI 回答不满意、服务渠道多;
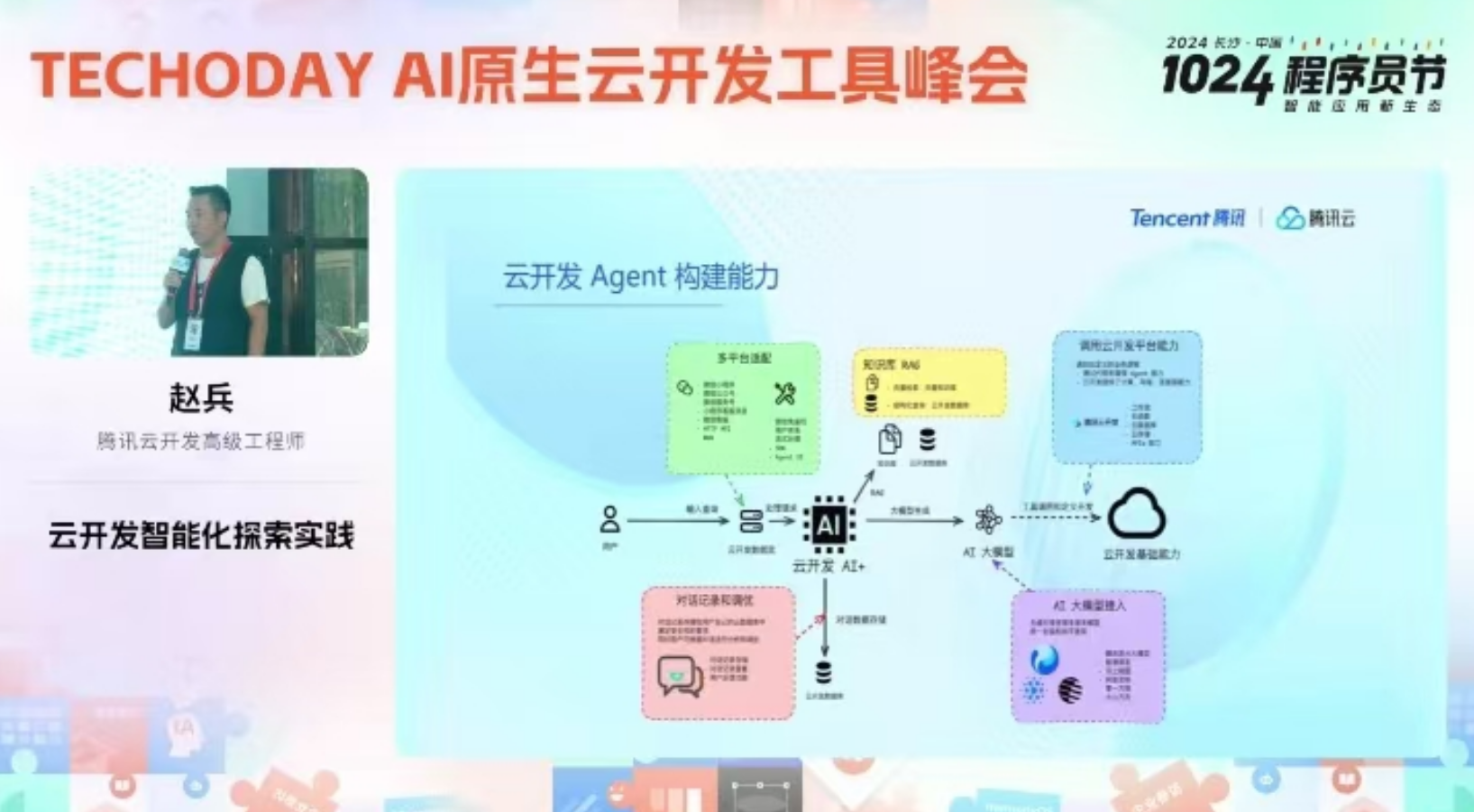
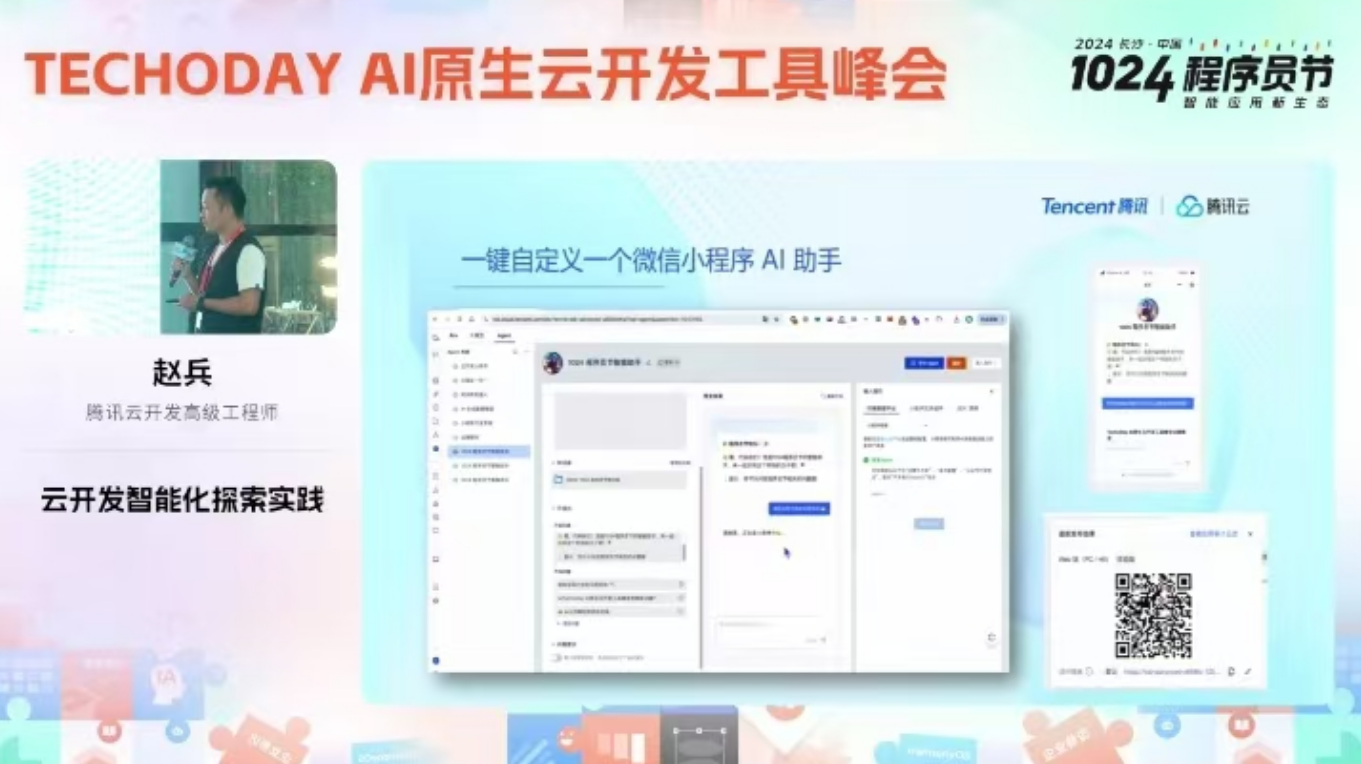
这款产品是 AI+,开箱即用产品。代码是现成的封装成各种模块,可以拖曳,开发界面其实就是微信小程序界面,用户依据实际业务情况,将所需求的模块拖曳至工作界面(即小程序界面)。
AI 回答的效果是什么?
例如,用户输入“生成图表”,大模型自动输出一些看板、数据表格。
如果要获得更加精准及灵活的回答,就要注重原子能力的多样性。


熊鑫 向量数据库
1.什么是向量数据库?
第一,词义范畴衍生。例如,你搜“水果”,大模型可以搜到所有相关结果;
第二,应用场景,包括客服、图搜视频、推荐,以及数据库清晰。
2.RAG
针对已有知识进行召回,匹配用户问题并回答;
如果没有学到知识,大模型就会连接外存,进行搜索,并就搜索结果进行推理。
3.RAG 入门易,上生产难
RAG 使用流程:
PDF/WORD 文件上传 - 拆分 - 截断(例,字符串长度限制) - 建模(文本向向量转化)。
具体步骤:
用户输入问题 - 向量化 - 数据库根式检索 - 生成提示词 Prompt
注意,这里推理使用的是 Long Chain。
4.Bad Cases
分享者查阅了存量客户的“问题”,并观察 AI 回答。例如,服务器怎么连不上了?AI 通常在回答之前,先排查问题在哪,再进行答案。
5.解析效果对比
(1)向量数据库。标题、合并表,都能处理得比较好;
(2)按照“标题”拆出 Chunk,每个 Chunk 都要进行去除空字符,以及其他修整;
(3)BM25 关键字检索功能。
6.架构
(1)上层应用:知识文档,FAQ,意图识别;
(2)下层数据库:向量,关键字召回,索引。其他生态建设:解析、拆分、嵌入。
7.腾讯向量数据库
(1)OLAMA,内部服务数据库,每天超过 8500 次访问;
(2)去年上线;
(3)性能:信通院权威报告,20 毫秒做到相似性检索。
8.双路召回 + ReRank 提升检索效果
(1)BM25 关键字检索;
(2)RRF 排名融合。这里理解为,排名-生成-排名-生成 ……














