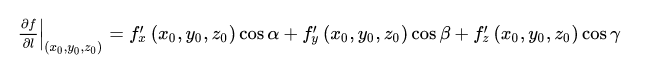DAY - 1
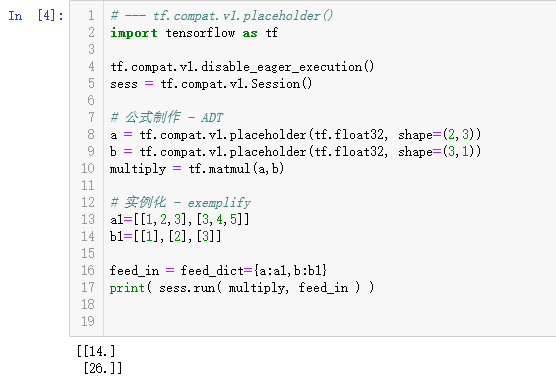
tf.compat.v1.placeholder() # 与 feed_dict={a:a1, b:b1} 一起用
tf.random.train.truncated_normal() # 返回一组向量
tf.nn.softmax()
tf.reduce_mean() # 正常的求均值的函数
tf.reduce_sum() # 正常的加和函数
tf.math.log()
tf.argmax()
tf.equal()
tf.cast()
DAY - 2
### 以下书上原活摘抄
第一章 深度学习简介
关于人工智能
1.关于计算机和人脑的关系
计算机发明是为了解决重复劳动。对人来讲的简单动作,对计算机来讲是个知识库。要让计算机掌握关于这个世界的知识。有些常识,对计算机来讲也是巨大挑战。
很大一部分无法明确定义的知识,就是人类的经验。比如我们需要判断一封邮件是否为垃圾邮件,会综合考虑邮件发出的地址、邮件的标题、邮件的内容以及的邮件收件人的长度,等等。
神经科学家发现,如果将小白鼠的视觉神经连接到听觉中枢,一段时间之后小鼠可以习得使用听觉中枢“看”世界。这说明虽然哺乳动物大部分为了很多区域,但这些区域的学习机制却是相似的。在这一假想得到验证之前,机器学习的研究者们通常为不同的任务设计不同的算法。
值得注意的是,有一个领域的研究者试图从算法层理解大脑的工作机制,它不同于深度学习的领域,被称为“计算神经学”Computational Neuroscience 。深度学习领域主要关注如何更加准确的模型来模拟人类大脑的工作。事实上,目前大家所熟知的“深度学习”基本上是深层神经网络的一个代名词,而神经网络技术可以追溯到 1943 年。
2.给出一个不严格的范式
“如果一个程序可以在任务 T 上,随着经验 E 的增加,效果 P 也可以随之增加,则称这个程序可以从经验中学习。”通过垃圾邮件分类的问题来解释机器学习的定义。
之所以说在大部分情况下,是因为逻辑回归算法的效果除了依赖于训练数据,也依赖于从数据中提取的特征。
同样的数据使用不同的表达方式会极大地影响解决问题的难度。一旦解决了数据表达和特征提取,很懂人工智能任务也就解决了 90%。深度学习解决的核心问题之一就是自动地将简单的特征组合成更加复杂的特征,并使用这些组合特征解决问题。
深度学习算法可以从数据中学习更加复杂的特征表达,使得最后一步权重学习变得更加简单且有效。深度学习可以一层一层地将简单特征,转化成更加复杂的特征,从而使得不同类别的图像更加可分。深度学习算法,可以从图像的像素特征中逐渐组合出线条、边、角、简单形状,复杂形状等更加有效的复杂特征。
3.How it works?
虽然人类神经元处理输入信号的原理目前还对我们来说还不是完全清晰,但 McCulloch-Pitts Neuron 使用简单线性加权和的 方式来模拟这个变换。
分布式的知识表达的核心思想是现实世界中的知识呵呵概念应该通过多个神经元(Neuron)来表达,而模型中的的每一个神经元也应该参与表达多个概念。例如,假设要设计一个系统来识别不同颜色不同型号的汽车,那么可以有两种方法。
文章中首次提出了反向传播的算法(back propagation),此算法大幅降低了训练神经网络所需要的时间。直到今天,反向传播算法仍然是训练神经网络的主要方法。
4.神经网络应用领域
Sepp 和 Juergen 于 1991 年提出的 LSTM Long Short-term memory,可以有效地对校长的序列进行建模,比如一句话或者一段文章。直到今天,LSTM 都是解决很多自然语言处理、机器翻译、语音识别、时序预测等问题最有效的方法。
以手写体识别为例,在 1998 年,使用支持向量机 SVM 的算法可以把错误率降低到 0.8%。
5.有多受欢迎?
关于 “deep learning” 关键词在搜索引擎中的搜索,2017 年是 2016 年的两倍,是 2015 年的四倍。
2012年时候,Hinton 教授利用深度学习技术将 ImageNet 图像分类错误降低到 16%。
在物体识别问题中,人脸识别是一类应用非常广泛的技术。它既可以应用于娱乐行业,也可以应用于安防、风控行业。在娱乐行业中,基于人脸识别的相机自动对焦,自动美颜,基本已经成为每一款自拍软件的必备功能。在安防、风控领域,人脸识别应用更是大大提高了工作效率并节省了人力成本。比如在互联网金融行业,为了控制贷款风险,在用户注册或贷款发放时候需要验证本人信息。
Yann 这个系统在 2000 年左右处理了美国全部支票的数量的 10-20%。
自然语言
在自然语言处理领域,使用深度学习实现智能特征提取的一个非常重要的技术,单词向量 word embedding。单词向量是深度学习解决很多上述自然语言处理问题的基础。
单词向量会将每一个单词表示成一个相对较低维度的向量(比如,100 维度,200 维度)。对于语义相近的词,其对应的单词向量在空间中的距离也应该接近。
在金融行业,可以通过深度学习分析语言的情感表达。Derwent 于 2012 年 5 月正式上线,世界首家通过社交网络 Twitter 上推文进行情感分析来指导证券交易的对冲基金公司。
1.4 深度学习工具介绍、对比
Tensorflow 是谷歌于 2015 年 11 月 9 日正式开源的计算框架。如今,包括 Uber、Snapchat、Twitter、京东、小米等国内外科技公司也纷纷加入使用 Tensorflow。
深度学习本身就是一个处于蓬勃发展的活跃程度,只有社区活跃度更高的工具,作者认为应该更加看重工具在开源社区的活跃程度。只有社区活跃度更高的工具,才有可能跟上深度学习本身的发展速度,从而在未来不会面临被淘汰的风险。
### 这里开始不是书上的原话
Tensorflow 主要依赖包 (1) Protocol Buffer (2)Bazel
其中。Protocol Buffer 是谷歌开发的处理结构化数据的工具。传输之前要序列化,要变成一串字符串。 和 XML 相比,Protocol Buffer 是一串二进制流;转换两次,先用序列化,然后转为特定的 Schema。Protocol Buffer 序列化之后的数据,比 XML 格式要小 3-10 倍,解析时间快 20-100 倍。
Protocol Buffer 保存在 .photo 中,每个 message 代表了一类结构化的数据,例如这里是用户信息。Protocol Buffer 可以是 message 也可以是另一些类型,布尔型、整数型、实数型、字符型。Protocol Buffer 是 Tensorflow 系统中使用的重要工具。
Bazel 是从谷歌开源的自动化构建工具。项目空间(workspace)是 Bazel 一个基本概念。一个项目空间,简单理解,就是一个文件夹, 包含了编译一个软件所需要的源代码以及输出编译结果的软连接 symbolic link。Bazel 对 python 支持的编译方式要使用 python 语言,所以这里是以编译 python 程序为例。其中,py_binary 编译成可执行文件,py_test 编译 python 测试程序,py_library 将 python 程序编译成库函数供其他 py_binary 或者 py_test。
编译的具体信息是通过定义 name, srcs, deps 等属性完成的。
第二种方式是 docker。将 Tensorflow 以及 Tensorflow 所有依赖封装到 docker 镜像中。
### TF 入门
张量和图的概念
(1)TF 用 placeholder 先设置变量 ,但是没有实例化;
(2)使用 Session 开启一种“命令”,命令所有变量都实例化,产生数值。
值得注意的是,TF 里的程序基本可以用 节点 和 关系 来描述,也就是画在“图”上。
关于如何开启“会话”?
(1)# 创建会话
sess = tf.Session()
sess.run()
sess.close()
(2)# 创建会话
with tf.Session() as sess:
sess.run()
Playground TensorFlow
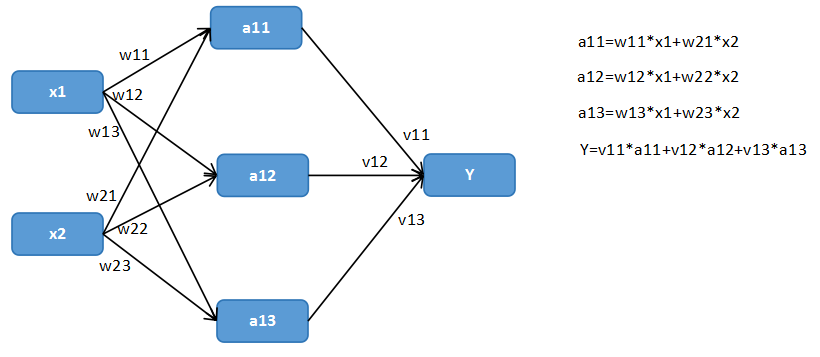
特征向量提取对机器学习来说至关重要。神经网络的每个节点都输出一直实数值,通过一个输出值和一个预先设置的阈值,就可以得到最后的分类结果。以判断零件合格。一般可以认为当输出值离阈值越远时候,得到的答案越可靠。
神经网络通过通过对参数的合理设置,来解决分类或者回归问题。神经网络优化过程,是优化神经元中参数取值的过程。神经网络有若干个全连接层,之所以称为全连接是因为任意两个节点之间都有链接。我们这样来解释的神经网络的隐藏层。
神经网络中的参数是神经网络实现分类或者回归问题中重要部分。本小节将更加具体地介绍 TensorFlow 是如何组织、保存以及使用神经网络中的参数的。在 TensorFlow 中,变量(tf.Variable)是作用就是保存和更新神经网络中的参数。和其他编程语言类似。TensorFlow 中的变量也需要指定初始值。
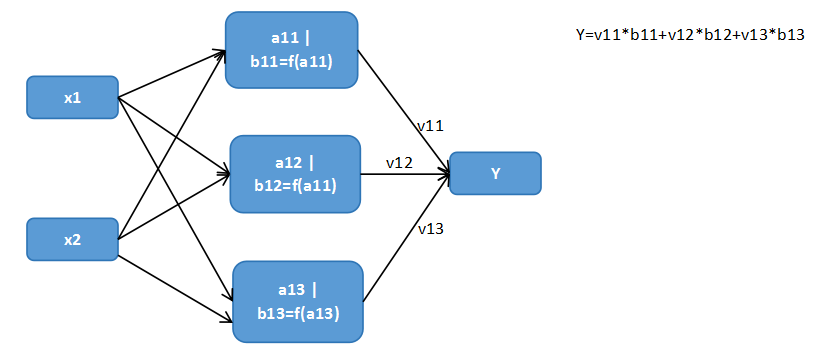
第一张图是神经网络 behave 的最初模型。现在用的是第二张图,在神经元还有个激活函数(注意和损失函数区别)。由于神经元在传播的时候,是用激活函数映射过,因此属于非线性模型。毕竟,直接把线性组合作为输入,输入下一层神经元的时候,模型还是线性系统。
注意,激活函数常用的三种:ReLU, Sigmoid, tanh 。注意第二、第三种都是 S 型的。
关于 tf.Variable()
在 Tensorflow 程序的第二步会声明一个会话(session),并通过会话计算结果。在上面的样例中,当会话定义完成之后就可以开始真正运行定义好的计算了。但是在计算 y 之前,需要将所有用到的变量初始化。初始化所有变量。
init_op=tf.initialize_all_variables()
sess.run(init_op)
变量定义是在 tf.Variable() 定义的,类型定义好之后,是不改变的。
关于 tf.placeholder()
placeholder 是 feed_dict 是配套起来使用的。sess.run( 某个公式变量, feed_dict = {} )。feed_dict 注意输入的是 JSON 格式。如果 tf.placeholder 是在 Graph 在画布(或者舞台)上,标记几个记号,关键在于,你标记的时候规定了方的、圆的、三角的。feed_dict 的时候,也是按照你一开始规定的形状,不是按照后来修改的。如果您是上周一在画布上放置方的记号,这周一就决定放置圆的记号,那您使用起来是非常劳累的。
线性模型的特点,即任意 线性模型的线性组合仍然是线性的。通过线性变换,任意层的全连接神经网络和单层神经网络模型的表达能力没有任何区别,而且它们都是线性模型。神经网络模型中参数的优化过程直接决定了模型的质量,是使用神经网络时非常重要的一步。
第四章 深层神经网络
之所以要用深层神经网络是因为浅层网络解决不了问题。其实,要讲清楚项目怎么做是比较麻烦的,最好的情况是写得清楚,像教科书那样。
首先,要明确,如果没有激活函数,那么所有神经网络都是线性传导。这意味着模型提升也是线性的,解决这个问题方式就是增加“激活函数”。因此这里介绍三个激活函数。
(1)ReLU 这个函数是 x>0 才有输出,否则 y=0
(2)Sigmoid 常用,S型曲线,作用是 Diverge 输入
(3)tanh 也是 S 型曲线
再者,经典损失函数 H(p,q)= -∑p(x)log(q(x)),含义即交叉熵的含义。TF 在这里还介绍了离散的 Sigmoid 算法。交叉熵刻画两个概率分布的距离,也就是说交叉熵越小,两个概率分布越接近。
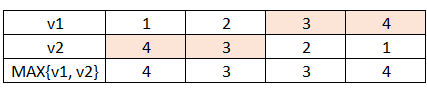
接着,自定义损失函数 loss = tf.reduce_sum( tf.select( tf.greater(v1, v2), (v1-v2)*a, (v2-v1)*b ) )
关于神经网络的优化。
神经网络模型中的参数优化过程直接决定了模型的质量,是使用神经网络时非常重要的一步。一是优化每次迭代的前行方向。
(1)随机梯度下降法 Stochastic Gradient Descent。这个算法优化的不是在全部训练数据上的损失函数,而是在每一轮迭代中,随机优化某一条训练数据上的损失函数。梯度下降算法和随机梯度下降算法有缺点,在实际应用中一般采用这两个算法的折中 —— 每次计算一小部分训练数据的损失函数。这一小部分数据被称之为一个 batch。通过矩阵计算,每次在一个 batch 上优化神经网络的参数并不会比单个数据慢太多。另一方面,每次使用一个 batch 可以大大减小收敛所需要的迭代次数。
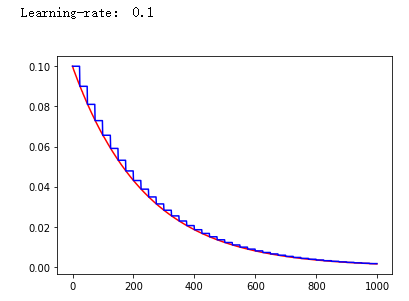
(2)学习率的优化。学习率总的来说不能太小也不能太大,通常用指数下降法,指数衰减法。
decayed_learning_rate = learning_rate * decay_rate ^ (global_step/decay_steps)
解决过拟合问题。两种正则化方法,一是 L1 ∑abs(w); 二是 L2 ∑w^2。
关于损失函数
首先,了解什么叫做“优化问题”,优化问题分成目标和约束,目标通常都是最大化损失函数,或者最小化损失函数。而约束,就是完成你的目标过程中,不能干的部分。
通常目标就是为了做预测,为了用一个“算法”将输入的向量进行计算,输出一套预测值,如果预测值和真实值足够接近的时候,那么算法就是好的。否则算法就不够好。
因此,目标放置一个损失函数,通常使得 ∑(y_hat - y)^2 达到最小。当然这本书这里不是使用这个损失函数。
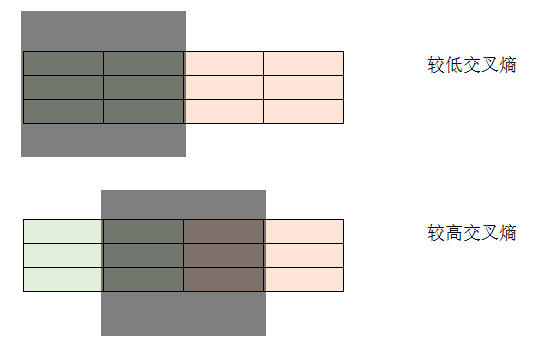
关于交叉熵(Cross Entropy)
H(p,q) = - ∑p(x)log(q(x))
交叉熵
周老师的西瓜书。交叉熵 = - ∑p(x=1)log(p(x=1))
信息增益 = 好坏瓜交叉熵 - 变量i交叉熵
变量i交叉熵 = -∑[变量i取值j的比例 * ∑p(j_hit)log(p(j_nothit))]
挑选变量的时候,选择信息增益较大的变量。因为计算公式中“好坏瓜交叉熵”是固定的,因此变量i交叉熵越小越好。请看示意图。
随机梯度下降
书中对于随机梯度下降法没有解释得特别清楚,这里找到知乎上的一篇文章。点击阅读《
如何理解随机梯度下降(stochastic gradient descent,SGD)? 》。
“如果使用梯度下降法(批量梯度下降法),那么每次迭代过程中都要对 个样本进行求梯度,所以开销非常大,随机梯度下降的思想就是随机采样一个样本 来更新参数,那么计算开销就从 O(n) 下降到 O(1)。” —— 知乎原话
传统梯度下降算法是求平均的,那么,为什么我们没有自信用一个样本来计算梯度呢?我只要在每次选择计算梯度的样本,使用随机选择方法,就有可能达到和求平均同样的效果。这时候 随机梯度下降算法的 basic idea。
图 传统梯度下降
因此随机梯度算法,随机选择一个样本进行梯度计算。最后再补充方向导数的公式。注意,既然是导数,一定是个数值。
第四章的函数及演示
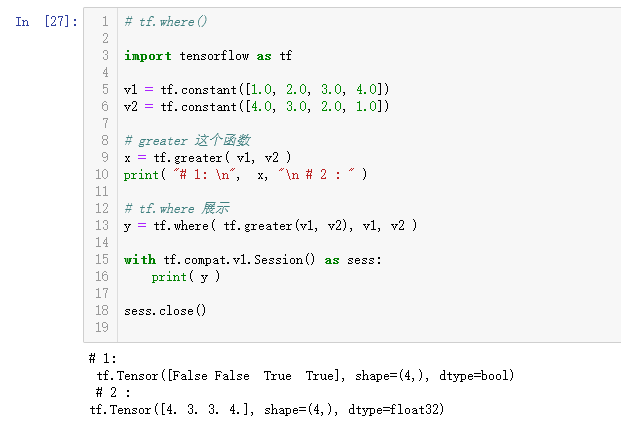
关于 自定义损失函数,tf.greater() 展示。其中 tf.select() 需要略作调整,改成 tf.where()。
示意图
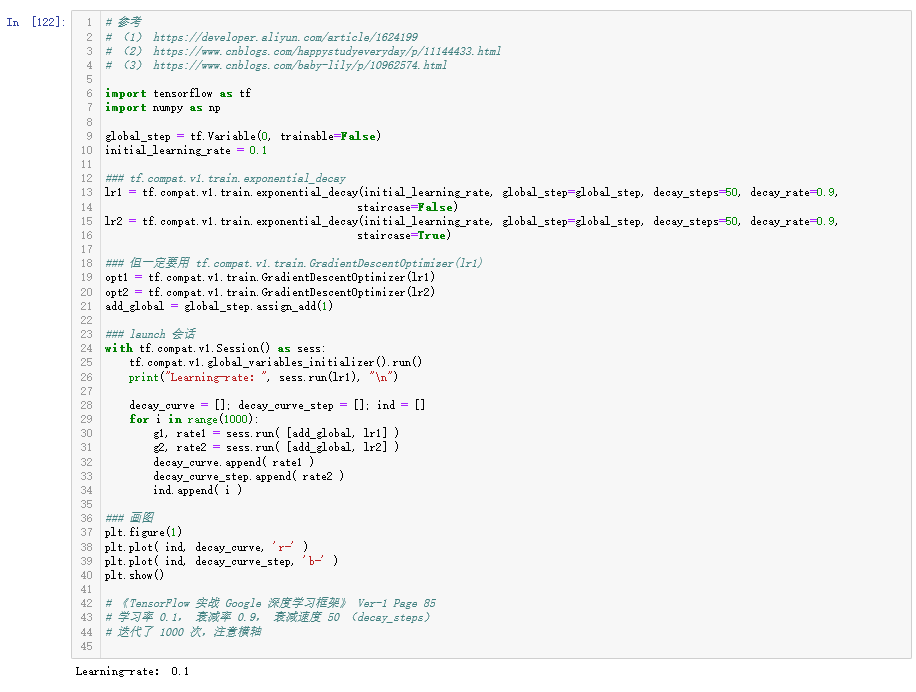
关于 学习率衰减。书上给出的是指数衰减,书上给出的函数公式还是可以使用的,其公式 decayed_learning_rate =
learning_rate * decay_rate ^ (global_step/decay_steps)
使用的是 tf.compat.v1.train 中的函数: tf.compat.v1.train.exponential_decay()
画图图像
关于 过拟合 问题
一是关于“过拟合”,因模型是用于预测未来的,建模是为了找到变量共性部分。如果对于过去的信息吸收得过多,则会产生“过拟合”问题。同样的,如果过去的信息代入模型的太少,则称为“欠拟合”。二是解决“过拟合”也简单,如果模型过于复杂,将过去的信息带入太多,则指示数值较大;如果过去信息带入太少,则指示数值较小。我们称为“正则项” R。三是关于损失函数 loss,该数值通常都是越小越好,又由于 loss = loss + R,一旦正则项变大的时候,意味着更新的步骤方向并不是非常好。
为了衡量模型复杂度 R,其计算出来的数值太大,说明模型过于复杂。通常分为 L1 和 L2 正则项。
L1 = |w1| + |w2| + ...
在 TF 中,两个函数可以计算 L2,分别为 tf.keras.regularizers.l1(0.5)(weights) 和 tf.nn.l2_loss(weights)。而 L1 计算方式,tf.keras.regularizers.l2(0.5)(weights)。代码方面,书上的代码暂时无法直接运行出,所以用 keras.regularizers.l2()。
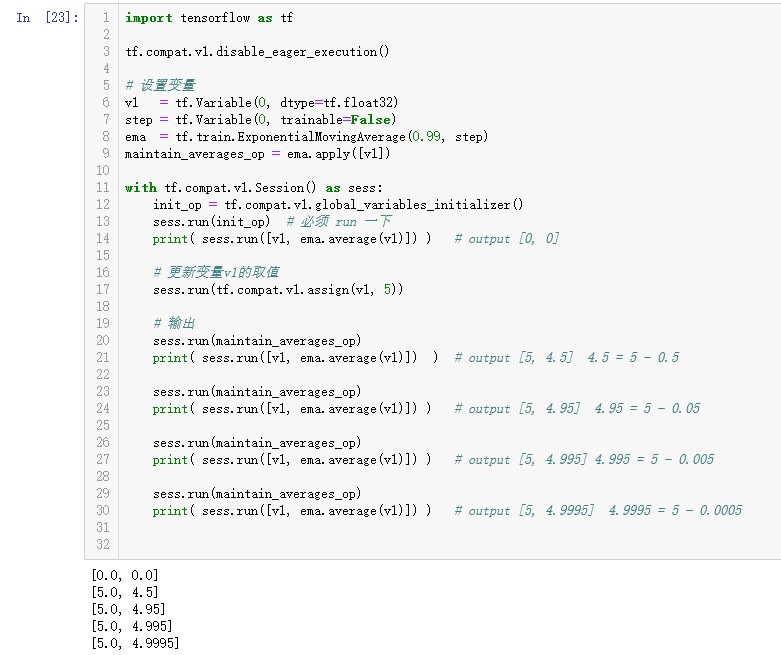
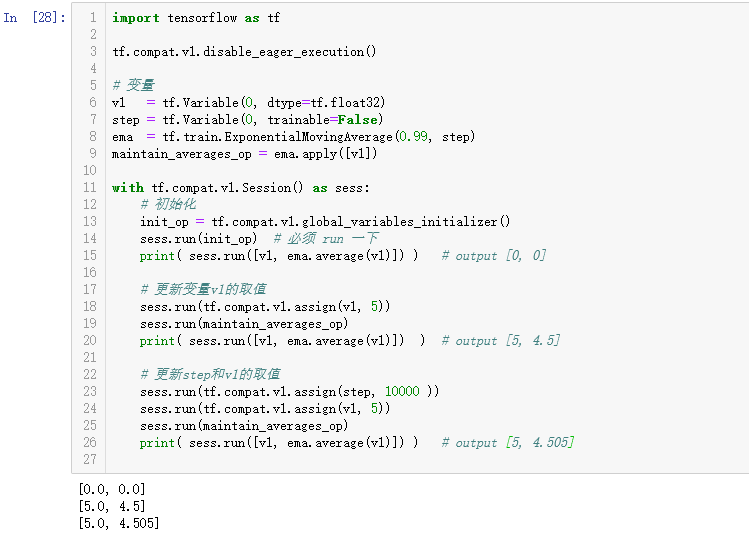
关于“滑动平均模型”
在 TensorFlow 实战这本书上写的是,在使用随机梯度下降算法的时候,会用滑动平均模型。主要是复制一个影子变量,和影子变量作滑动平均。什么意思呢?
先来看看 tf.train.ExponentialMovingAverage() 的作用。
关于 EMA 中的 STEP 设定,时间关系,暂时就不展开了!!!真的很难!!!
其次知道这个模型的作用。滑动平均可以看作是变量的过去一段时间取值的均值,相比对变量直接赋值而言,滑动平均得到的值在图像上更加平缓光滑,抖动性更小,不会因为某次的异常取值而使得滑动平均值波动很大。
在迭代的时候利用以下公式维护好之前的信息:
f(t) = b * f(t-1) + (1-b) * g(t)
其中,b 是(0,1)上的常数,f(t) 是影子变量 shadow_variable,而 g(t) 是迭代变量本身,称为 variable。注意,影子变量 f(t) 初始值即 X 输入矩阵,和参与迭代的变量 g(t) 是一样的。这么做是为了图片信息在迭代的过程具有某种“稳定”。那么影子变量和变量怎么求呢?
公式(1) Corrected f(t) = f(t) / (1-b)
其中,shadow_variable 即 f(t),variable 即 g(t),decay 即 b。decay 迭代公式
decay = MIN{ decay, (1+num_updates)/(10+num_updates) }
关于上述的 num_updates,网上资料比较少,如果真的用到的时候,就认为可以调整 decay —— 这样理解总没错吧!至此,第四章总结完毕。我要去跑步了!!!
参考文献
[1] 鲤鱼与驴(2022),详解Inception结构:从Inception v1到Xception,稀土掘金,2022 [2] 小绿叶(2019),洞悉Inception网络结构,知乎,2019 [3] 吴攀(2017),无需数学背景,读懂 ResNet、Inception 和 Xception 三大变革性架构,机器之心,2017 [4] 西檬饭(2020),InceptionTime: Finding AlexNet for Time Series Classification,CSDN,2020 [5] 知乎-阿尔吉侬(2022),InceptionNet系列网络汇总,知乎,2022 [6] Sunshineski(2022),深度学习笔记:如何理解激活函数?(附常用激活函数),知乎,2022 [7] Jackpop(2022),如何理解随机梯度下降(stochastic gradient descent,SGD)?点赞 165 回答,知乎,2022 [8] 何永灿(2018),Volcano!,博客园,2018 [9] zz的aly(2024),TensorFlow学习笔记(一): tf.Variable() 和tf.get_variable()详解,阿里云,2024 [10] 是大高呀(2019),tensorflow之tf.train.exponential_decay()指数衰减法,博客园,2019 [11] Baby-Lily(2019),TensorFlow——学习率衰减的使用方法,博客园,2019 [12] Jerry199(2020),tensorflow 中的L1和L2正则化,博客园,2020 [13] 郭大瘦(2017),TensorFlow中滑动平均模型介绍,阿里云,2017 [14] wuliytTaotao(2018),理解滑动平均(exponential moving average),博客园,2018 [15] MicMind(2022),指数滑动平均(EMA:exponential moving average)[转],知乎,2022