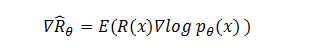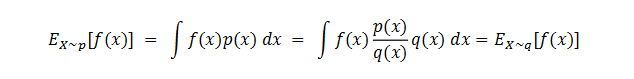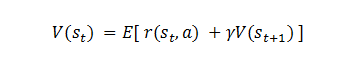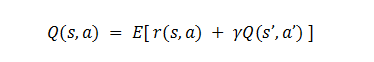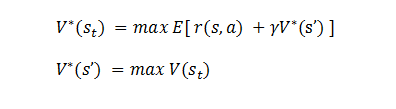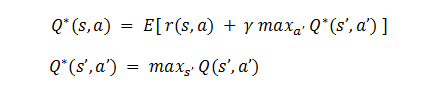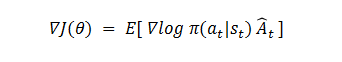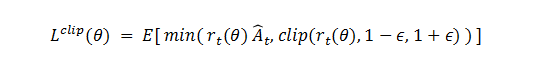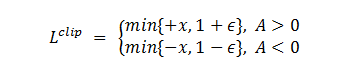01 免模型离线强化学习
课堂笔记:分布产生偏差,对于分布估计不到的样本过于乐观。分布外偏移,由于分布外的决策及偏移,这样对于“预测”产生干扰。提出的解决方法是,样本内学习。若样本内学得够好,理论上,分布外会产生决策限制,换言之,要是估计乐观的话,估计指标就设置得“悲观”些;要是估计悲观的话,估计指标就设置的“乐观”一些。分布内进行标准强化学习。
ShoelessCai 评注,坦率地讲,因准备不足,听课效率并不高。那么,我们先复习一些先导知识吧!
问题一:在线强化学习 v.s.离线强化学习
据资料显示,在线或者离线翻译为 Online,或者 Offline,它们在学习过程中使用数据的方式不同。
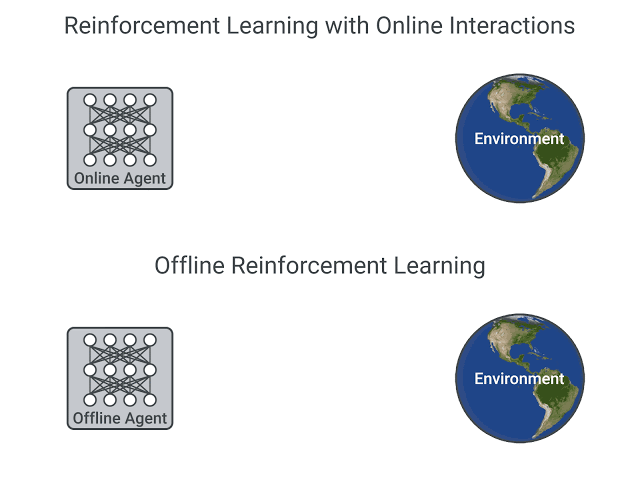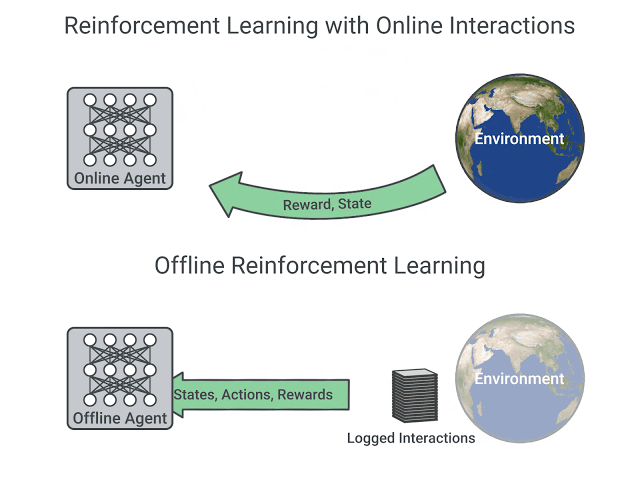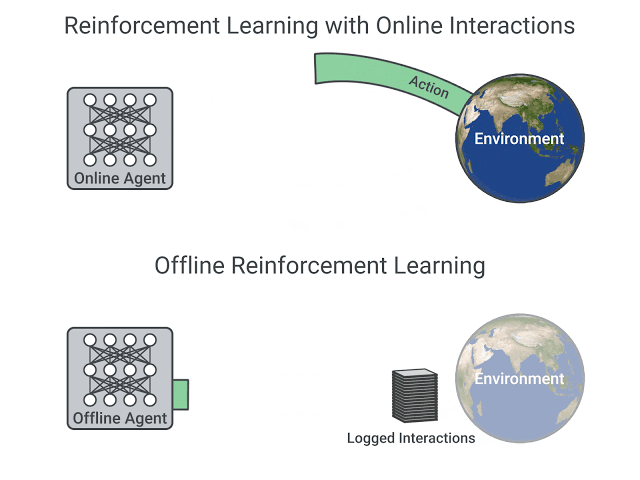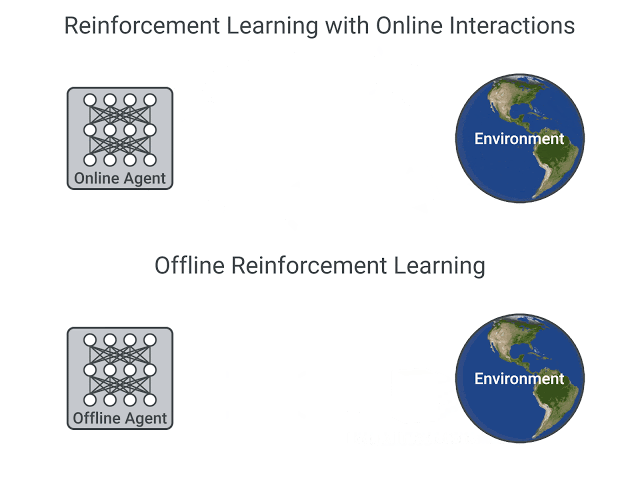
离线强化学习是一种在不与环境交互的情况下进行学习的过程。它直接从已有的数据集(通常是由其他策略收集的数据)中学习。这种学习方式不依赖于实时交互,因此可以处理大规模数据集,并在不需要实时反馈的情况下进行训练。离线强化学习的一个关键假设是,用于学习的数据集是近似最优策略产生的数据。这意味着,通过分析这些数据,智能体可以学习到接近最优的策略。ShoelessCai 评注,有点“存在即最优”的假设。
在线强化学习则强调在与环境的实时交互中进行学习。在这种方法中,智能体在与环境交互的过程中逐步收集数据,并立即使用这些数据进行学习。ShoelessCai 评注,在线学习的 Response 是实时的。
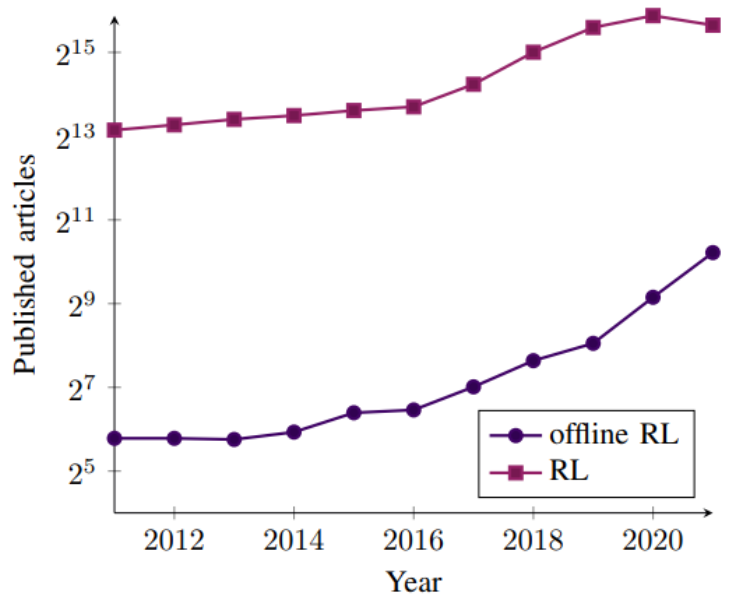
不难发现,Offline Learning 的论文数量正在逐年增加。
图片来源:腾讯云-深度强化学习实验室,2022
问题二:On-policy v.s. off-policy
On-policy和off-policy这两个词在强化学习领域非常重要,知乎上有很多关于其讨论强化学习中on-policy 与off-policy有什么区别?,最典型的莫过于李宏毅老师下棋形象例子解释,还可以从以下方式解释:
“[补充] 两者在学习方式上的区别:若 agent 与环境互动,则为 on-policy(此时因为agent亲身参与,所以互动时的 policy 和目标的 policy 一致);若 agent 看别的 agent 与环境互动,自己不参与互动,则为 off-policy(此时因为互动的和目标优化的是两个 agent,所以他们的 policy 不一致)。”ShoelessCai 评注,一是从这个定义来看,on-policy 就是 Online 的意思。二是在线学习的“策略一致性”与离线学习的“策略不一致性”。三是 on-policy v.s. off-policy 也翻译成“同策略”与“异策略”。
继续上述引用:
“两者在采样数据利用上的区别:on-policy,采样所用的 policy 和目标 policy 一致,采样后进行学习,学习后目标 policy 更新,此时需要把采样的 policy 同步更新以保持和目标 policy 一致,这也就导致了需要重新采样。off-policy,采样的 policy 和目标的 policy 不一样,所以你目标的 policy 随便更新,采样后的数据可以用很多次也可以参考。”ShoelessCai 评注,上文“随便更新”其含义比较模糊,我们暂时认为,离线学习的策略是不一致的,因此更新的时候,并非简单的参数更新,很可能是结构更新。
基于这段引用,我们提出以下几个问题:
(1)Online 和 on-policy 差别是什么?
(2)Off-policy 的时候,策略如何更新?on-policy 如何更新策略?
针对第一个问题,online/offline 是从能否和环境交互来说的,on-policy和off-policy是算法利用的是不是当前这个策略的数据来评价自己。
针对第二个问题,on-policy方法指的是那些需要直接使用通过当前策略生成的数据来更新模型的算法,这类方法通常关注于改进当前正在使用的策略本身,而不是依赖之前收集的数据。下面以SARSA和A3C(Asynchronous Advantage Actor-Critic)为例,说明on-policy是如何更新模型的。
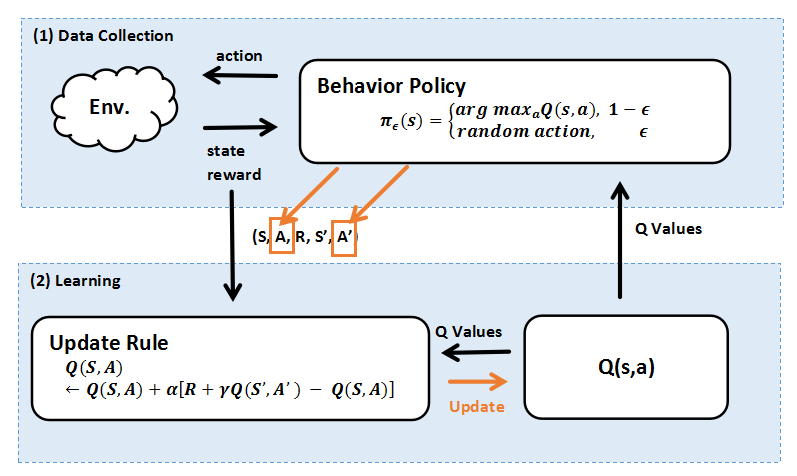
(A) SARSA
SARSA是一种经典的on-policy时序差异(Temporal Difference, TD)学习算法。涉及五个要素:状态(State)、动作(Action)、奖励(Reward)、下一个状态(Next State)以及下一个动作(Next Action),即(S, A, R, S', A')。SARSA根据当前策略采取行动,并使用以下公式更新Q值(该值表示从某状态开始,采取某个行动后能获得的预期回报):
图片来源:知乎-小错,2025
与后文的 off-policy 作对比,on-policy 在返回 Reward 的时候,将这一轮 action A 和下一轮的 action A' 都确定了,这个过程由样本计算梯度得出。
(B) A3C
A3C是Actor-Critic方法的一种变体,它利用多个并行环境来加速学习过程。在A3C中,存在两个主要的组件:actor和critic。actor负责学习采取什么行动,而critic则评估这个行动的好坏。具体来说,actor网络输出一个概率分布,用于指导当前状态下采取的动作选择;critic网络评估当前策略的好坏,即给出当前策略下未来的期望回报。A3C通过异步地运行多个agent实例,在不同的环境中探索,并使用它们的经验来更新共享的模型参数。这种更新包括调整actor部分的参数以优化动作选择策略,同时调整critic部分的参数以更好地评估策略的质量。
无论是SARSA还是A3C,关键在于它们都
依赖于当前策略生成的数据 进行学习和更新,这与off-policy方法不同,后者可以使用不同于当前策略所产生数据的学习方式。on-policy方法通常要求更频繁地更新策略,因为随着学习的进展,旧的数据很快就会变得不相关或过时。
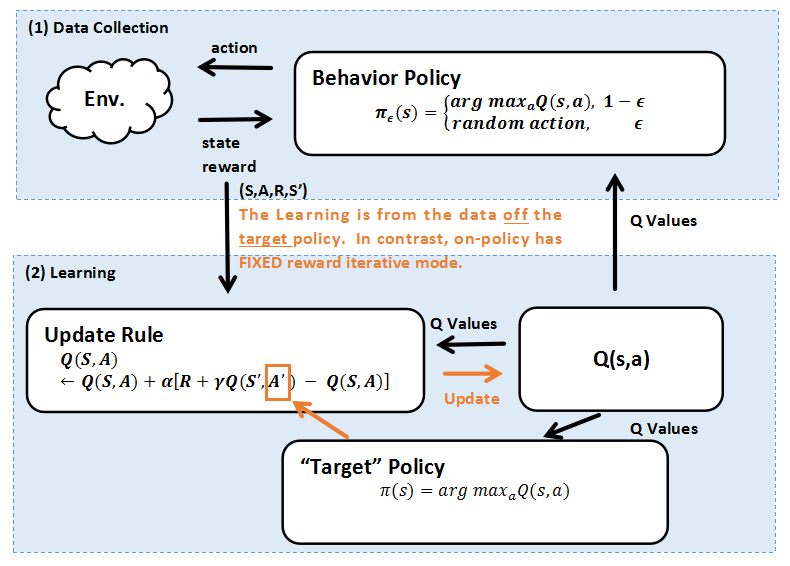
关于 off-policy。每一轮学习,分两个策略:行为策略(behavior policy)与目标策略(target policy)。行为策略是专门负责学习数据的获取,具有一定的随机性,总是有一定的概率选出潜在的最优动作。而目标策略借助行为策略收集到的样本以及策略提升方法提升自身性能,并最终成为最优策略。
《Reinforcement Learning An Introduction》有句话:“... the learning is from the data off the target policy.”。也就是说RL算法中,数据来源于一个单独的用于探索的策略(不是最终要求的策略),Q-Learning 就是一个例子,上述公式给出 Q-learning 迭代方法。
Q-learning 时序差分法估计策略
系数 α属于0-1区间,很小的正系数 ε。
图片来源:小错,2025
另一张示意图。on-policy 差异在于
“回报的更新方式” 。
针对 on-policy 的学习方法,最常用的是“回报梯度法”。即
问题三:On-policy “回报梯度法”很容易理解,为什么要推出 off-policy 呢?
利用参数 θ 来生成大量数据,然后基于这些数据更新参数θ,得到新的参数 θ'。但在得到 θ' 之后,原先的 θ 就不再适用了,因此必须用新参数 θ' 重新生成大量数据。这种不断重复生成数据的过程,使得整个流程较为繁琐,效率较低(知乎-Trancy Wang,2025)。ShoelessCai 评注,依据上述 off-policy 示意图,不难推断,使用 off-policy 评估 Reward 的时候,计算的“基数”是能够采取的 action 的个数。相较之下,on-policy 的“基数”是样本数。因此,off-policy 计算次数就大大减少了。这部分有待验证。
写到这里我们大致有个概念,on-policy 和 off-policy 差异在哪,如何更新的。
问题四:什么叫做“重要性采样”?
Importance Sampling,其基本思想,简单的分布在“重要”样本点上的累积概率比较一致,即
p(x)/q(x) → 1
那么我们可以进行如下操作。
这是一种具有普适性的“重要性采样”方法。假设随机变量 X 服从概率密度 p(x),为了估算 Reward,我们需要计算该分布的期望。然而 p(x) 极为复杂,对其进行计算或者采样操作都十分困难。为了解决这一难题,我们引入另一个概率密度 q(x),该分布相对简单,易于进行计算和采样。具体操作是,在计算期望的表达式分子分母同时乘以 q(x)。通过这样的处理,原本基于 p(x) 对 X 求期望的问题,就转变为基于 q(x) 对 X 求期望,不过此时期望的表达式变成了最终推导得出的式子(Trancy Wang, 2025)。
问题五:为什么 Q-Learning 可以不使用“重要性采样”?
Q-Learning 算法中的 Q函数,即 Q(s,a) 基于贝尔曼方程推出的,每一轮迭代实质上是找到最优的贝尔曼估计量。注意到,贝尔曼等式右侧的期望,只与状态转移分布有关而与策略无关,不论训练数据 (S,A,R,S') 来自于哪个策略,按照 Q-Learning 的更新式代入数据,都能使 Q 函数接近 Q_star(s,a) 。因此,Q-Learning 可以不采用重要性采样。同样,DQN 算法也是如此(小错,2025)。
问题六:贝尔曼方程
通俗地讲,贝尔曼方程就是回报与 Q 最优加权平均,Q 最优即策略行动 A 对应的价值。
贝尔曼方程:
状态最优
动作最优
贝尔曼最优方程:
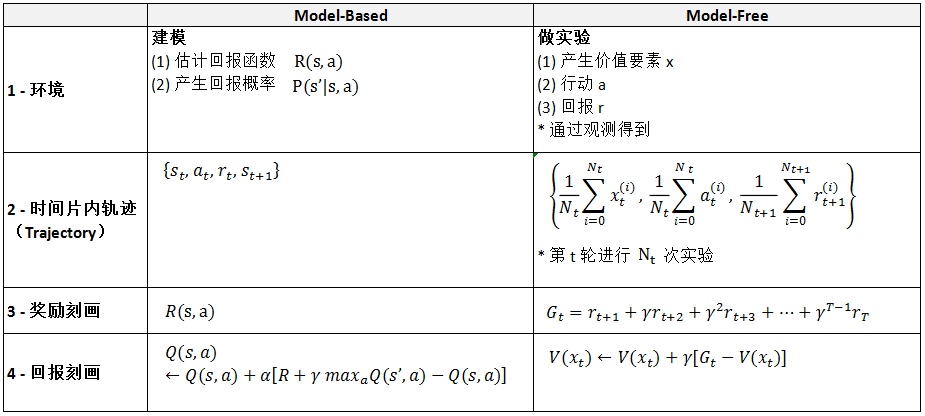
问题七:何为免模型 Model-Free?
(1)关于 Model-Based
基于模型的强化学习(Model-Based Reinforcement Learning, MBRL)。首先,上述理论都是为了建树免模型强化学习。无模型强化学习(Model-Free RL),因为它们直接学习策略函数或者价值函数,并没有对环境进行建模。只能通过和真实环境交互来采集数据,是有限制的,一个典型的问题就是数据效率不高。
人类通过少量的观察,就能够对环境进行建模,并利用这些模型进行规划和决策。如何做到呢?简言之,人类能够理解环境的动态特性,并在此基础上进行推理。因此,如何利用环境模型来提高样本效率,成为强化学习领域一个重要的研究方向。
MBRL 算法的核心思想是,通过学习环境的动态模型和奖励函数,利用这些模型进行规划和决策,从而提高样本效率。与 Model-Free RL 直接学习策略或价值函数不同,MBRL 首先学习环境的内在模型,然后利用这个模型来指导策略的学习和执行。形式化地说,我们可以将环境建模为一个马尔可夫决策过程(Markov Decision Process, MDP)。
在 MBRL 中,我们首先学习环境模型 P(s'|s,a) 和 R(s,a),然后利用这些模型进行规划和决策。也就是说,我们通过与环境交互,收集轨迹(trajectory)数据 {s(t), a(t), r(t), s(t+1)}, 然后利用这些数据学习模型的参数,例如使用监督学习或者动态规划的方法。有了模型之后,智能体可以使用该模型在脑海中模拟与环境的交互,进而选择最佳的动作。
(2)关于 Model-Free
上述模拟环境的函数 P(s'|s,a) 和 R(s,a) 也可以不建模出来,而直接使用“实验法”,称为“免模型法 Model-Free” 。以蒙特卡洛采样法为例,每次采样,观察环境展示的“转移状态”和“奖赏”,经过多次采样,求取平均累积奖赏作期望。
轨迹
{x(0), a(0), r(1), x(1), a(1), r(2), ... ,x(T-1), a(T-1), r(T), x(T)} ~ π
累积奖励
G(t) = r(t+1) + r(t+2)·γ + r(t+3)·γ^2 + ... + r(T)·γ^(T-1)
经过求极限和近似,得到价值函数
V(x(t)) ← V(x(t)) + α[ G(t) - V(x(t)) ]
(3)总结 Model-Based(MB) v.s. Model-Free(MF)
前者针对环境估算采取策略之后,环境产生“函数依赖”的回报 R(),以及回报产生的概率 P()。每一个时间片轨迹 {s0,a0,r0,s1}。生成价值函数
G(t) = r(t+1) + r(t+2)·γ + r(t+3)·γ^2 + ... + r(T)·γ^(T-1) #Gain
V(x(t)) ← V(x(t)) + α[ G(t) - V(x(t)) ] #Value
同时,MF 方法直接获取与价值相关要素 x,行动变量 a,回报 r。产生轨迹
{x0, a0, r1, x1, a1, ... rT, xT}
累积奖励的计算,是一组关于回报的平滑。关于下一轮价值函数估计,与这一轮价值函数估计相关,与累积奖励相关。
Q(s,A) ← Q(s,A) + α[ R + γMax(a){Q(s',a)} - Q(s,A) ]
#Q()是价值函数
#a∈A 实际操作是遍历
02 通过单向信息建模 克服视觉语言的特征污染
课堂笔记:任务,视频监控,目标跟踪,目标检测。跟踪、检测的区别。识别之后,可以不进入训练,持续跟踪。有噪声进入语言特征。纯视觉信息;视觉及语言信息。视觉信息流、语言信息流。token 化之后加一层(adapter),进入视觉 token 集合。应用方面,用在摄像头监测。
关于 Adapter Layer
Adapter Layer 通常用于计算机视觉或者 NLP 领域,针对其展望也包括在之前时间点智能体未能作出最优决策的情况下,Adapter Layer 是否能修复智能体的决策?Adapter Layer 是通过 PPO 计算的。
关于 PPO 算法
近端策略优化(Proximal Policy Optimization, PPO)算法作为一种高效的策略优化方法,在深度强化学习领域获得了广泛应用。特别是在大语言模型(LLM)的人类反馈强化学习(RLHF)过程中,PPO扮演着核心角色。本文将深入探讨PPO的基本原理和实现细节。PPO属于在线策略梯度方法的范畴。其基础形式可以用带有优势函数的策略梯度表达式来描述:
其中,A 是优势函数,是“演员-评论家”算法的目标函数,PPO 是对该方法的改进和优化。另外,π是关于参数向量θ的函数,计算梯度时候,也是针对θ计算梯度。这个公式依据行动产生的价值,取值期望。
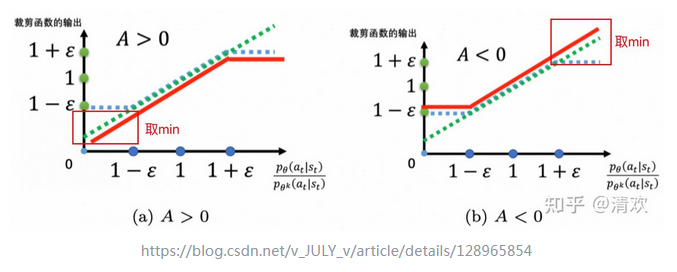
PPO 损失函数,是时间维度上求期望,公式如下。
PPO 图形示意,以及 clip() 函数含义。
图片来源:
机器学习十大算法系列,2025 关于 ViT
ViT 也是 Transformer 的一种。Transformer 原本是为了解决语言文字处理任务而提出的模型,其设计初衷是用于建模序列数据中的长距离依赖关系。在 NLP 领域中,Transformer 能够通过自注意力机制灵活地捕捉单词之间的全局关系,极大提升了语言理解与生成的能力。而谷歌的研究团队提出了非常大胆也非常优雅的一个思想:如果我们能把图像切割成小块(Patch),再把每个 Patch 当作一个“词”,是否也能将图像转化为序列,从而让 Transformer 也能处理视觉信息?而其提出的ViT 就是这样做的:它将一张图像划分为固定大小的 Patch(如 16×16),将每个 Patch 展平成向量,通过一个线性投影层将其映射到统一的维度空间,最终形成一个 token 序列。随后,ViT 在这个 token 序列前加上一个可学习的 [CLS] token,并叠加位置编码(Positional Encoding),以保留图像中的空间位置信息。整个序列就像一段文本,送入多层标准的 Transformer 编码器结构进行处理,最后通过 CLS token 的输出,完成整张图像的分类任务。这种方法不依赖任何卷积操作,完全基于序列建模,展现了 Transformer 在图像建模上的巨大潜力(SkyXZ,2025)。
常用的CV模型有:VGG系列、Resnet系列、Densenet系列、inception系列、Googlenet系列以及效果最佳的Efficientnet系列、GAN系列、数据增强系列、注意力机制系列等等。常用的NLP模型有:RNN、Seq2Seq、Transformer、GRU、GPT、LSTM、Bert系列、Elmo、 XLNet等(诸葛孔暗,2021)。
03 白帆老师 复旦博士
企业原油数据新城 MCP 放入列表,大模型阅读列表。大模型通过 MCP 接口操作。通过接口暴露能力。绝大部分智能体访问到统一的数据库。
发现错误的方式:一是前置分析;二是执行异常;三是后置分析。纠错手段,直接抛弃,完全人工、暂停、撤销。
访问控制:一是加个超时机制。二阶段检索设计。
答疑:权限控制比较感兴趣。是否可以放开智能体的权限。理论上可以做到,事实上,智能体的权限是会被严格控制的。如果人工派单,一天2次导入,使用智能体效率会大幅提升。不审核,有问题直接回退。
这类知识库的建设,概念上很像某种网盘,接受文本的网盘。文本分段,映射到场景业务内容。查询向量,拿出 5-10 个输入,作为之后的输入。是能力还是知识,如果是能力,就要修正模型,如果是知识,就调整知识库。
参考文献
[1] 阿里通义千问
[2] php是最好的(2024),离线强化学习与在线强化学习:基础概念与区别,百度开发者中心,2024 [3] 马小疼(2023),online/offline和on-policy/off-policy这两种标准有什么区别?,知乎,2023 [4] 深度强化学习实验室(2022),离线强化学习(OfflineRL)总结(原理、数据集、算法、复杂性分析、超参数调优等),腾讯云,2022 [5] 小错(2025),强化学习中的奇怪概念(一)——on-policy与off-policy,知乎,2025 [6] Trancy Wang(2025),强化学习进阶(二)- on-policy to Off -policy 到PPO1/PPO2,知乎,2025 [7] tsyhahaha(2023),强化学习Chapter3——贝尔曼方程,博客园,2023 [8] 格兰芬多燕南支部(2024),第二节 贝尔曼方程(Bellman Equation),知乎,2024 [9] Finch(2025),如何理解 PPO-CLIP 目标函数中的 clip 和 min 操作?过犹不及论,知乎,2025 [10] Deephub(2025),近端策略优化(PPO)算法的理论基础与PyTorch代码详解,阿里云,2025 [11] 知乎用户8Gs7DZ(2023),Proximal Policy Optimization (PPO) 算法理解:从策略梯度开始,知乎,2023 [12] Anonymous(2024),ADAPTER-RL: ADAPTATION OF ANY AGENT USING REINFORCEMENT LEARNING,OpenReview,2024 [13] tomsheep(2025),【强化学习教程 19】Model-based RL综述,知乎,2025 [14] LB's Home(2017),【强化学习】免模型学习(Model-Free) ,Github,2017 [15] SkyXZ(2025),合集 - 深度学习(2),博客园,2025 [16] 诸葛孔暗(2021),深度学习:剖析计算机视觉CV与自然语言处理NLP的发展和选择(CV与NLP的落地场景、研究领域、方法模型、工作前景、方向选择),知乎,2021