关于计算机视觉 Computer Vision 和 自然语言 Natural Language Programming 算法,整理如下。
常用的CV模型有:VGG系列、Resnet系列、Densenet系列、inception系列、Googlenet系列以及效果最佳的Efficientnet系列、GAN系列、数据增强系列、注意力机制系列等等。常用的NLP模型有:RNN、Seq2Seq、Transformer、GRU、GPT、LSTM、Bert系列、Elmo、 XLNet等(诸葛孔暗,2021)。
01 关于 Vision Transformer (ViT)
ViT 也是 Transformer 的一种。Transformer 原本是为了解决语言文字处理任务而提出的模型,其设计初衷是用于建模序列数据中的长距离依赖关系。在 NLP 领域中,Transformer 能够通过自注意力机制灵活地捕捉单词之间的全局关系,极大提升了语言理解与生成的能力。而谷歌的研究团队提出了非常大胆也非常优雅的一个思想:如果我们能把图像切割成小块(Patch),再把每个 Patch 当作一个“词”,是否也能将图像转化为序列,从而让 Transformer 也能处理视觉信息?而其提出的ViT 就是这样做的:它将一张图像划分为固定大小的 Patch(如 16×16),将每个 Patch 展平成向量,通过一个线性投影层将其映射到统一的维度空间,最终形成一个 token 序列。随后,ViT 在这个 token 序列前加上一个可学习的 [CLS] token,并叠加位置编码(Positional Encoding),以保留图像中的空间位置信息。整个序列就像一段文本,送入多层标准的 Transformer 编码器结构进行处理,最后通过 CLS token 的输出,完成整张图像的分类任务。这种方法不依赖任何卷积操作,完全基于序列建模,展现了 Transformer 在图像建模上的巨大潜力。
ViT 的第一步操作,就是将输入图像转化为一系列的 视觉 token,这个过程被称为 Patch Embedding,Patch 指的就是分割后的一小块图像区域。
第二步,在完成 Patch Embedding 得到形如 [batch_size, 196, 768] 的 Patch Token 序列后,接下来我们要做两件关键的事情:一是添加 [CLS] Token —— 图像的“全局摘要”入口,这里的“全局摘要”可以理解为小拼图的位置信息。二是添加位置编码(Positional Embedding)—— 帮助模型理解“图像中的位置”。这里我们举个例子,依据 ViT 算法,将图像[224.224,3] 分成 14*14 个小拼图的话,假设某块拼图是“纯色”的,那么这块拼图周围有 Edge(RGB数值骤变)的概率是很低的,但是一旦周围拼图有 Edge,那么周围第二块拼图有 Edge 的条件概率就很高了。
这是第三步。Transformer Encoder 也译成“Transformer 编码器”,即 Multi-head Attention + LayerNorm + MLP + 残差连接。一是 LayerNorm,这是将矩阵映射到 [0,1] 上数值的操作。二是 Attention 是有固定的公式,依据公式计算。三是前馈神经网络,也称为 MLP 子模块,处理残差的,公式如下(SkyXZ,2025)。
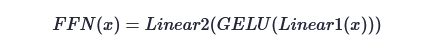
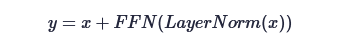
第四步,深度特征提取之后,应该获得形如 [batch_size, 196+1, 768] 的向量,根据作者的说法,可以直接分类了。据说,因为神经网络交互过程中,信息被平滑和传递得比较好。注意,这里细节没有深入展开,比较直觉地理解。
这里还有一篇文章的阅读,以及
参考文献
[1] SkyXZ(2025),合集 - 深度学习(2),博客园,2025
[2] 诸葛孔暗(2021),深度学习:剖析计算机视觉CV与自然语言处理NLP的发展和选择(CV与NLP的落地场景、研究领域、方法模型、工作前景、方向选择),知乎,2021














