封面故事:6.1 那天,20 个小朋友玩耍,4 个在摆摊。这是他们出售的商品。Jingyi 拍摄
伙伴们好,这几个礼拜坚持写周报、跑会、写会议纪要、读书及读书笔记。
2025 年 6 月 21 日于华东师范大学数据科学与工程研究院研究生学术沙龙第 43 期,正好学习到计算机视觉领域的 Transformer,即 Vision Transformer,简称 ViT。
点击《
华师大第 43 期研究生学术沙龙 》,获取更多信息。
01 一些简单的 numpy 函数
关于 TF 变量
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
# 每个 passage 之前都要用,处理 placeholder 传导的
a = tf.constant([1,3,4])
a = tf.cast( a, tf.float32 )
b = tf.exp(a)
with tf.compat.v1.Session() as sess:
print( sess.run( b ) )
[ 2.7182817 20.085537 54.59815 ]
关于 np.repeat(), np.tile()
import numpy as np
import pandas as pd
a = np.repeat( np.arange(3), 2 )
b = np.tile( [0,0,0,1,1,1,2,2,2], 3 )
c = a.reshape(-1,1) # 变成 2d
d = c.reshape(-1,1)
d
array([[0],
[0],
[1],
[1],
[2],
[2]])
关于 np.arange()
e = np.arange(95,99).reshape(2,2) #原始输入数组
e
array([[95, 96],
[97, 98]])
关于 np.pad()
np.pad(e,((1,1),(1,1)),'constant',constant_values = (0,0))
# np.pad(obj, ((up, bottom),(left, right)), 'constant', constant_values=(0,0) )
array([[ 0, 0, 0, 0],
[ 0, 95, 96, 0],
[ 0, 97, 98, 0],
[ 0, 0, 0, 0]])
这些函数主要为了看懂第四篇文献,暂时看懂程度一般。先放一放。
参考文献
[1] 秋风一片叶(2014),Intel Pentium CPU计算加减乘除的指令周期,博客园,2014
[2] Stack Overflow(2022),乘法和加法运算所需的时钟周期,腾讯云,2022
[3] 悟道修炼中(2018),测试运算所需时钟周期数,CSDN,2018
[4] 西西嘛哟(2020),【python实现卷积神经网络】卷积层Conv2D实现(带stride、padding),博客园,2020
02 关于手写 Conv2D
(1)如何手写 conv2D,从第一篇文献来看,是嵌入前传和和后传每一层网络。
(2)这篇是 知乎-pizh12thu 的文章,解释了卷积的原理,以及卷积消耗硬件计算资源的原因。
离散形式的卷积,计算如下。

(3)Halide 和 GEMM
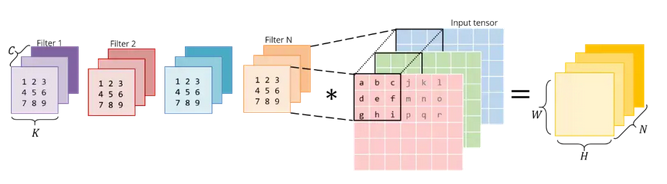
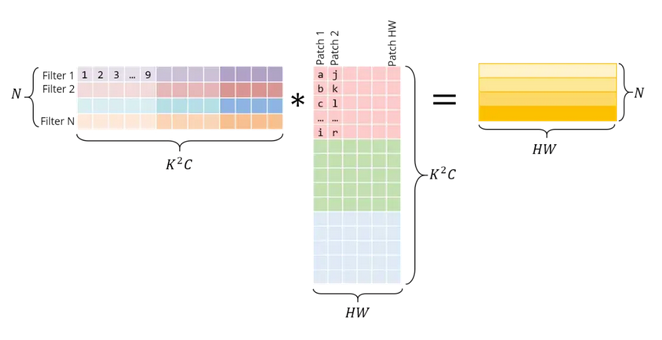
左边是横向 concatenate,右边是纵向 concatenate,注意,不仅仅是卷积之后的元素是列向量优先,而且 RGB 三个矩阵也是纵向拼接。
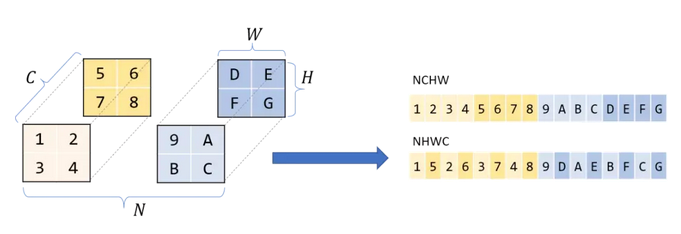
举个例子,N 样本量,C 通道,H 高度,W 宽度。
NCHW 通道置于长宽之前,按矩阵,即矩阵 R、矩阵 G、矩阵 B。
NHWC 通道置于长宽之后,RGB、RGB、RGB ……
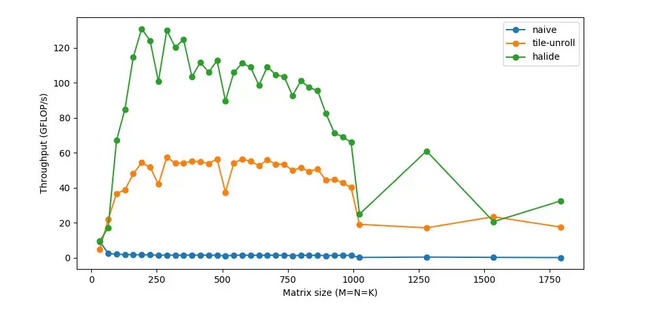
关于参考文献(1),主要讨论不干预情况下,每秒处理FLOP 随着矩阵维度增加的变化。以及若干种改进之后的情形。实验包括:
(a) reorder(ijk->ikj),
(b) tile-vec(SIMD),
(c) parallel(threading 将一个任务自分多线程),
(d) unroll(比如检查循环终止、更新循环计数器、指针算法等。相反,如果我们手工编写重复循环语句并展开循环,我们可以减少这种开销),
(e) halide(c++中的一种嵌入式语言,用来帮助编写快速图像处理代码。通过分解算法和计划,可以更容易地试验不同的优化。我们可以保持算法不变,并使用不同的策略)。
Btw,算法并不是所有都看懂。自己笔记如下。
(1)GEMM
GEMM 比较好理解,按照上述的方式任何卷积,都可以变成矩阵相乘。只要对 Filter 按行展开之后,行优先和列优先排列,这波操作称为“im2col”。GEMM 全称 Generalized Matrix Multiplication。
(2)Halide
Halide::Buffer C, A, B;
Halide::Var x, y;
C(x,y) += A(k, x) *= B(y, k);
(3)Tile
为了防止计算大矩阵时候内存产生“抖动”(频繁换入换出不同的矩阵内容),索性取矩阵的一小块,就像铺设瓦片一样。函数编写的时候,规定输出输入的位置(即长度),xo,yo,xi,yi。
(4)FMA
Fused Multiply-Add 融合乘加算法。即使用专用硬件计算乘法、加法。
(5)SIMD
Single Instruction Multiple Data 单指令多操作。相同 CPU 周期内,多个同时执行的操作。如果过同时运行 4 个数据点的 SIMD 指令,速度提升 4 倍。
(6)Threading
多内核,每个内核执行多个指令,一个程序把自己分成多个线程。相同工作负载,线程工作时间更少,与彼此同步时间更多。
(7)Unrolling
注意,4 个句子 2 个迭代,好于 1 个句子 8 迭代。然而,循环累积之后,代价都是巨大的。额外 2-3 条指令,都会使得成本很快增加。循环开销变得相对小,那么好处就开始减少。
接下来看一下 Attention 和 Convolution 的效果。
我一直理解成 Edge Detection,当然也可能讲 ML 的老师对很多算法的理解就是 Detection,例如,Edge Detection,Anomaly Detection,等等等。我拿 MNIST 卷了一层的效果。

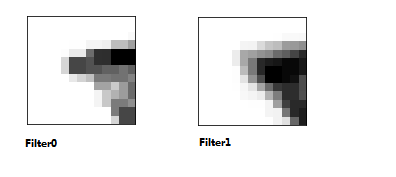
这是文章中 Attention 的效果。很多文献介绍 Self-Attention,解释成记录全局变量信息。

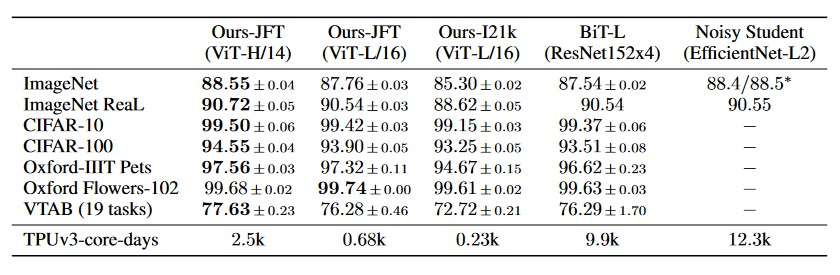
最后,文献(7)亮点是提出了 Transformer 在 Computer Vision 的应用,同时行业的 state-of-the-art 是 CNN,程度无人能及。新的 Transformer(ViT)应用之后,发现效果还挺好的,特别针对中小图片,也就是平时最多的监控设备画面。以下是各种算法在各种数据集上的表现。其中,ViT-B 意为 ViT-Basic,ViT-L 意为 ViT-Large,ViT-H 意为 ViT-Huge。
关于通道数是这样的,在这篇文章《
TensorFlow 实战 Google 深度学习框架(四)》,不难发现第一层通道数 32,第二层通道数 64,这是怎么产生的呢?经过找寻线上资料,不难发现,32 即第一层卷积神经网络有 32 个卷积核,而 64 则含义第二层神经网络有 64 个卷积核。
依据上述卷积核的输出,不难理解 Pooling 之后只捕捉到数字的“一部分”,32 个卷积核的含义,即从 32 个不同的部分捕捉手写数字的信息。那么第二层 64 即 64 个不同细节信息。
参考文献
[5] pizh12thu(2020),算法优化:卷积运算加速,知乎,2020
[6] AI 算法与图像处理(2019),解析卷积的高速计算中的细节,一步步代码带你飞,知乎,2019
[7] Alexey(2021), AN IMAGE IS WORTH 16x16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE, Google Research, 2021
[8] ML 小小白(2021), 关于卷积神经网络中的“输入通道”和“输出通道”的概念, CSDN, 2021
[9] Jingyi(2025),TensorFlow 实战 Google 深度学习框架(四) , ShoelessCai, 2025
[10] 全栈程序员站长(2022),tensorflow模型查看参数(pytorch conv2d函数详解), 腾讯云, 2022














