新闻
论文
直播
应用
登录
English
首页
>
新闻 > 文章
机器学习:基于 Gradient Boosting 的民宿预订问题分析
- 2022 -
12/12
13:39
零号员工
发表时间:2022.12.12 作者:Jingyi 来源:ShoelessCai 阅读:1066
摘要
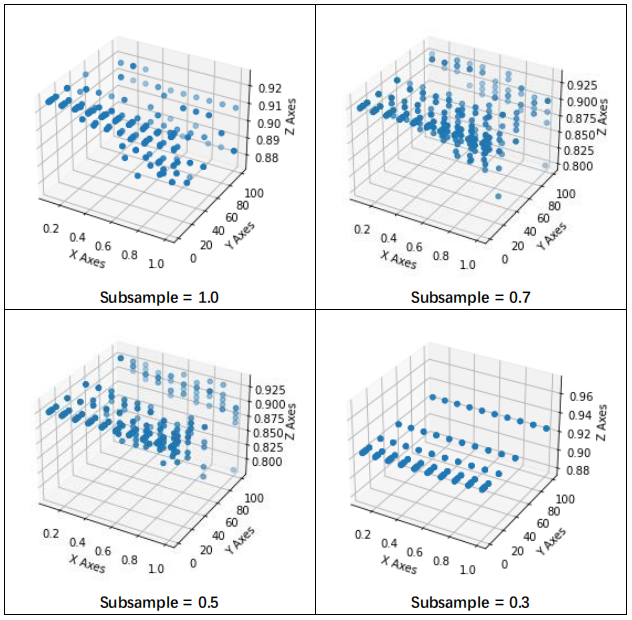
本篇主要考察GBDT(更精确的是 sklearn.ensemble.GradientBoostingClassifier)关于预测准确率和学习率、子模型数量、模型最大深度三个参数的变化关系。具体做法是,分割两个数据集,用 x_train 进行训练,考察 x_test 的准确率。
结论
针对 GBDT 这类模型,子模型数量 n_estimators 、学习率 learning_rate 都是非常重要的参数,对于预测的准确率 Accuracy 具有无法忽略的作用。然而,单个模型的最大深度 max_depth 起到的作用并不大。
应用
通过该实验,理解 Boosting 模型中哪些参数会起到比较大的作用,提升建模直觉。另外,文章简述机器学习如何通过目标函数和损失函数结合的模式,每次迭代到最优拟合,帮助建模人员提示阅读模型的能力,使得数据分析更加智能。
¥ 1.00
¥ 0.00
阅读全文
原文链接
长按/扫码,有您的支持,我们会更加努力!
阅读用户协议
0
最新评论
TOP 5 精选
回到顶部
回上一级
写文章
最新资讯
关于本司内部员工行为守则规范
一起逛 2026 中国国际金融展
直播笔记
《思考快与慢》读书笔记之四:为什么损失时更冒险
《思考快与慢》读书笔记之四:为什么损失时更冒险
ShoelessCai 科学背单词计划
Test 1.3 / Page 300: Company Speaker
听力训练:关于储蓄,男女有差异吗?
脱不花《沟通的方法》学习笔记 第一部分
高级口译:五分钟背单词(视频,Episode 25-37)
《思考快与慢》读书笔记之一:通才与专才的差异
热点话题
银行工作态度大调查
彭博推送 | 孟加拉国的不确定未来
碳酸锂,10年暴涨,可能持续至2024年
自行车王国2.0:“夜骑长安街” 成北京夜间运动新风尚
编年体简要外太空法案史(1915-2022)
精品论文
天池大赛:淘宝母婴购买情况数据分析
双重差分(DID)方法看“上海自贸区”十年业绩
机器学习的单样本预测可信度问题
基于时间序列及机器学习的上证指数实证研究
基于反向传播神经网络的 Airbnb 数据分析
基于反向传播神经网络的 Airbnb 数据分析
有你的鼓励
ShoelessCai 将更努力
文档免费。保护知识产权,保护创新。
ShoelessCai.com —— 我们致力于,
商业
赋能行业。