关于《TensorFlow实战Google深度学习框架》最后几个章节还是展开一些。
第六章 卷积层
这个名词专门出出现在“卷积神经网络”,在其他的文章中我有说到过,卷积的 Filter 和图片的矩阵进行运算之后,抽取的是局部特征。为了更加明显地显示这个特点,我找了一些卷积之后的图片。Btw,首次学习 BPNN 是在 Cousera 上,当时讲课的老师这么说的,也不是笔者总结的。

这些图片是经过两个 Filter 卷积层作用之后的结果,不难发现,这些是手写数字的边界,虽然非常模糊,但是能够用肉眼识别是局部特征。
那么,卷积层是怎么计算的呢?笔者在网上搜索了三张动图来解释清楚 Filter 是按照怎样的顺序计算的。

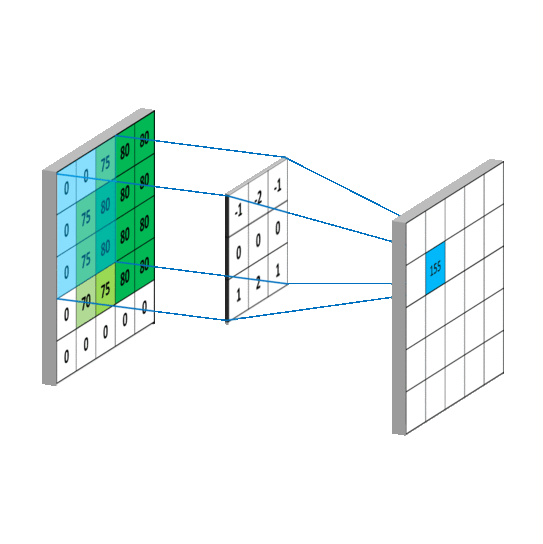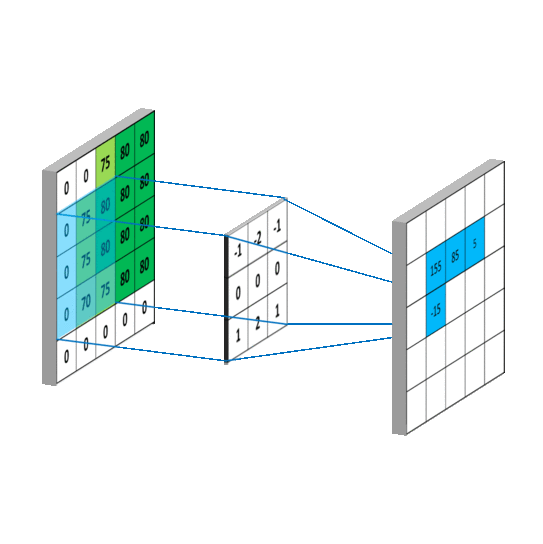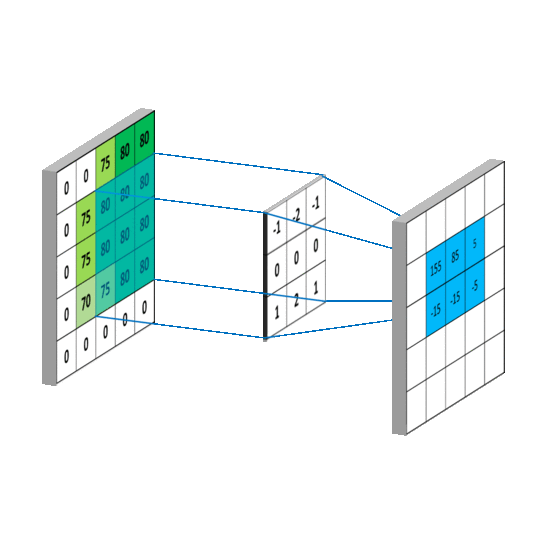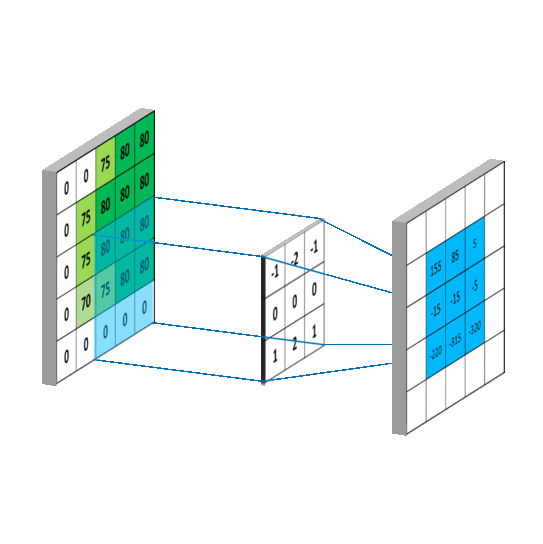
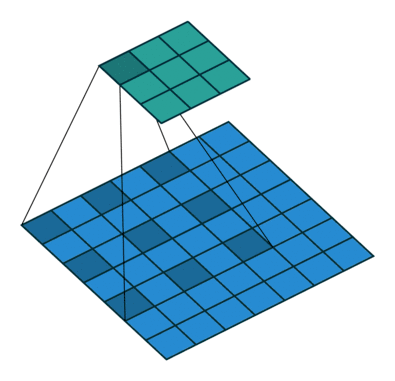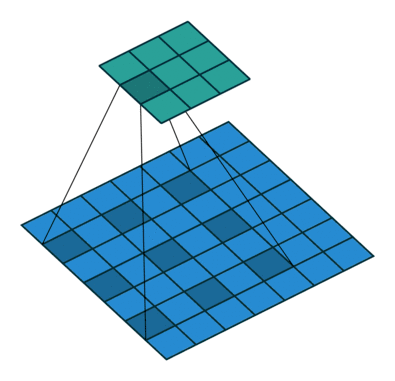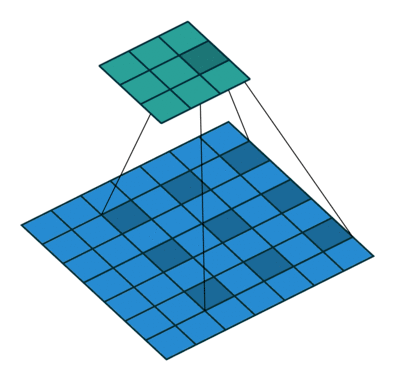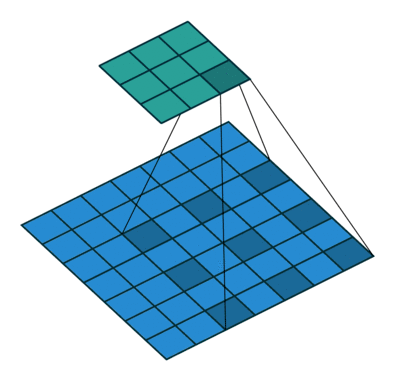
这样,我们可以比较全面地了解到卷积层的作用。
第六章 池化层
池化层,英语 Pooling,简单粗暴地理解为,信息太多了,每个区域找个代表,这个代表可以是最大值,也可以是平均值。
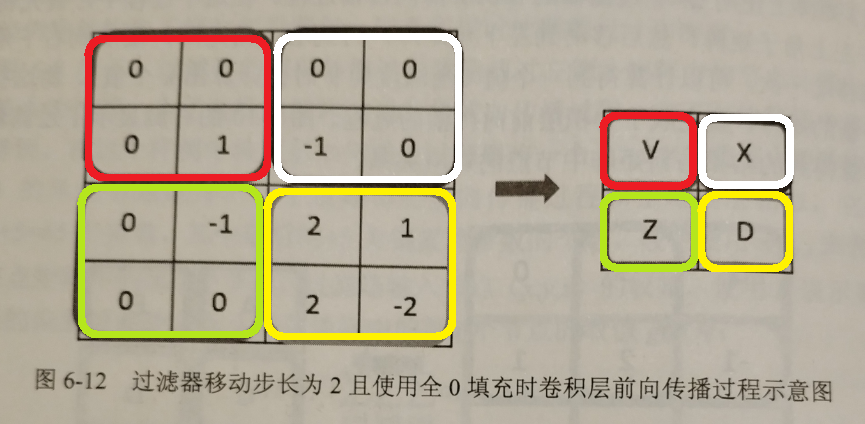
不同于卷积层的计算方式,针对池化层,我自己总结为满足 MECE 法则,即池化层 Filter 覆盖原来矩阵的时候,是完全穷尽互不相交的。同时,再复习卷积层,卷积层是逐个格子向前进的。
这是第一版第 144 页的图片,我用手机拍照上传的,稍微作了点色彩化处理。
第六章 经典金句原话
这里是书上原话。
本章节将介绍一个非常常用的神经网络结构 —— 卷积神经网络(Convolutional Neural Network CNN)。卷积神经网络的应用非常广泛,在自然语言处理、医药发现、灾难气候发现甚至围棋人工智能程序中都有应用。本章还将详细讲解卷积层和池化层的神经网络模型来介绍如何设计卷积神经网络的架构以及如何设置每一层神经网络的配置。
相比其他算法,卷积神经网络可以得到更低的错误率。而且通过卷积神经网络达到的错误率已经非常接近人工标注的错误率了。在 MNIST 数据集的一万个测试数据上,最好的深度学习算法只会比人工识别多错一张图片。
无论是 MNIST 数据集还是 Cifar 数据集,相比真实环境下的图像识别问题,有 2 个最大的问题。第一,现实生活中的图片分辨率要远高于 32*32,而且图像的分辨率也不会是固定的。第二,现实生活中的物体类别很多,无论是 10 种还是 100 种豆远远不够,而且一张图片中不会只出现一个种类的物体。为了更加贴近真实环境下的图像识别问题,有斯坦福大学的李飞飞带头整理的 ImageNet 很大程度地解决了这两个问题。
ImageNet 是一个基于 wordNet 的大型图像数据库。在 ImageNet 中,将近 1500 万图片被关联到了 wordNet 的大约 20000 个名词同义词集上。目前每一个与 ImageNet 相关的 wordNet 同义词集都代表了现实世界中的一个实体,可以被认为是分类问题中的一个类别。
ImageNet 图片上用几个矩形框出了不同实体的轮廓。在物体识别问题中,一般将用于框出实体的矩形称为 bounding box。
ILSVRC 2012 图像分类数据集包含了来自 1000 个类别的 120 万张图片,其中每张图片属于且只属于一个类别。因为 ILSVRC 2012 图像分类数据集中的图片是直接从互联网上爬取得到的,所以图片的大小从几千字节到几百万字节不等。
在图像分类问题上,很多学术论文都将前 N 个答案的正确率作为比较的方法,其中 N 的取值一般为 3 或 5。在更加复杂的 ImageNet 问题上,基于卷积神经网络的图像识别算法可以远远超过人类的表现。
2013 年之后,基本上所有的研究都集中到了深度学习算法上。
卷积神经网络在 6.1 中的介绍的所有图像分类数据集上有非常突出的表现。前面章节介绍的神经网络没两层之间的所有节点都是有边相连的,所以本书称这种网络结构为全连接层网络结构。
以图像分类为例,卷积神经网络的输入层就是图像的原始像素,而输出层中的每一个节点代表了不同类别的可信度。
在 TensorFlow 中训练一个卷积神经网络的流程和训练一个全连接神经网络没有任何区别。
使用全连接神经网络处理图像的最大问题在于全连接层的参数太多。
参数增多除了导致计算速度减慢,还很容易导致过拟合问题。所以需要一个更合理的神经网络结构来有效地减少神经网络中参数个数。卷积神经网络就可以达到这个目的。
关于池化层。池化层,Pooling Layer,可以非常有效地缩小矩阵的尺寸,从而减少最后全连接层中的参数。使用池化层既可以加快计算速度也有防止过拟合问题的作用。
使用最大值操作的池化层被称之为最大池化层(Max Pooling),这是被使用得最多的池化层结构。
第六章 LeNet-5 模型简介
第一层 卷积层。
第二层 池化层。
第三层 卷积层。
第四层 池化层。
第五层 全连接层。形状不变。
第六层 全连接层。
第七层 全连接层。
第六章 Inception-v3
Inception 基本思想,不确定哪个 Filter 有用,索性全部都作用上去,然后再深度上进行连接,全部入模型,最后那些样本被选择得最多,说明哪个 Filter 最好。注意,如果 Filter 大小不一致的话,被映射变小的矩阵用 Padding “填充”0 即可,通常都是“填充”一圈。
第六章 迁移学习介绍
所谓迁移学习,就是将一个问题上训练好的模型通过简单的调整使其适用于一个新的问题。
例如,原来在 ImageNet 上训练好的 Inception 模型,怎么用于其他的图像分类问题呢?这套动作就称为“迁移学习”。
第七章 图像数据处理
第八章 循环神经网络
书上原话,本站会区分出自己的观点的。
循环神经网络 Recurrent Neural Network RNN,源自于 1982 年由 Saratha Sathasivam 提出的霍普菲尔德网络。霍普菲尔德网络因实现困难,在其提出时并且没有被合适地应用。该网络结构也于 1986 年后被全连接神经网络以及一些传统的机器学习算法所取代。然而,传统的机器学习算法非常依赖于人工提取的特征,使得基于传统机器学习的图像识别、语音识别以及自然语言处理等问题存在特征提取的瓶颈。而基于全连接神经网络的方法也存在参数太多、无法利用数据中时间序列信息等问题。随着更加有效的循环神经网络结构被不断提出,循环神经网络挖掘数据中的时序信息以及语义信息的深度表达能力被充分利用,并在语音识别、语言模型、机器翻译以及时序分析等方面实现了突破。
循环神经网络的主要用途是处理和预测序列数据。在之前介绍的全连接神经网络或卷积神经网络模型中,网络结构都是从输入层到隐含层再到输出层,层与层之间是全连接或部分连接的,但每层之间的节点是无连接的。
从网络结构上,循环神经网络会记忆之前的信息,并利用之前的信息影响后面节点的输出。也就是说,循环神经网络的隐藏层之间的节点是有连接的,隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出。
循环神经网络当前的状态 A(t) 是根据上一它最擅长解决的问题是与时间序列相关的。循环神经网络也是处理这类问题时最自然的神经网络结构。对于一个序列数据,可以将这个序列上不同时刻的数据依次传入循环神经网络的输入层,而输出可以是对序列中下一个时刻的预测,也可以是对当前时刻信息的处理结果(比如语音识别结果)。循环神经网络要求每一个时刻都有一个输入,但是不一定每个时刻都需要有输出。在过去几年中,循环神经网络已经被广泛地应用在语音识别、语言模型、机器翻译以及时序分析等问题上。
如之前所介绍,循环神经网络可以被看做是同一神经网络结构在时间序列上被复制多次的结果,这个被复制多次的结构被称之为循环体。如何设计循环体的网络结构是循环神经网络解决实际问题的关键。和卷积神经网络过滤器中参数是共享的类似,在循环神经网络中,循环体网络结构中的参数在不同时刻也是共享的。
循环神经网络的隐藏层的值 A(t) 不仅仅取决于当前这次的输入 X,还取决于上一次隐藏层的值 A(t-1)。
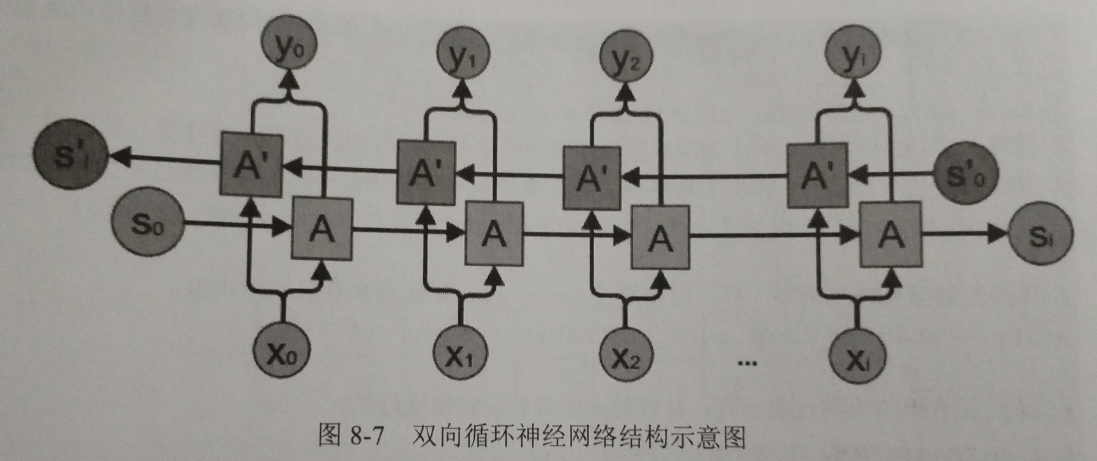
《TensorFlow 实战 Google 深度学习框架》第一版 Page 209
接下来,笔者用自己的话总结一下。循环神经网络示意图还是比较清晰的,基于这个示意图,我们提出几个关键点:
第一,权重矩阵在传播的时候,是直接传播,还是激活之后传播。答案是激活之后传播,事实上传的是 A(t) 这个矩阵。传播的方式,使用的是一组权重,这组权重有很多种算法,例如指数平滑。《TensorFlow 实战 Google 深度学习框架》第一版 Page 201。
第二,循环神经网络每个时间步的输入 X(t) 是新的内容吗?还是上一轮的预测的 Y_hat(t)。答案是 X(t) 新的内容,我们这样思考问题,鉴于循环神经网络是被应用在自然语言上的,如果要评价或者翻译一句哈的话,永远都有新的字或者词语作为输入,那么这个时候,一句话后面的“新词”就是我们所谓的 X(t)。也有种说法,说到 RNN 具有“记忆”功能,不但依赖于当前的输入,还依赖于之前的信息。怎么理解这句话呢?仍然考虑 Encoding a sentence 这样的任务。这个时候,RNN 作为您选择的算法,跑到后来有新单词输入的时候,这个时候又要考虑新单词的含义,又要考虑之前单词的含义。基于上述信息,笔者认为,X(t) 是新加入的内容。
第三,之前的信息,包括每个时间步的预测 Y_hat(t),以及每个时间步的权重矩阵 A(t)。这些信息怎么传呢?答案是,看公式。然而,笔者查询搜索引擎上的答案,还是比较繁杂,也会有各种表达方法。综合多方的资料,我们采取最常用的表达方式。
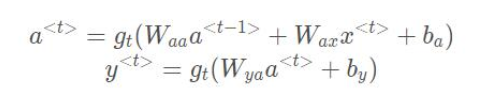
注意到,上一轮的预测 y_hat 收到 每一轮的 A(t) 影响,而决定 A(t) 是之前的 A(t-1) 以及新的输入 X(t)。其实,每一个时间步都会有 Loss 和 Y_hat 的计算。但是这些不会进入下一个时间步的计算,影响下一步的只有这一轮的权重 A(t-1) 以及未来的新单词(姑且这么理解吧!)X(t)。
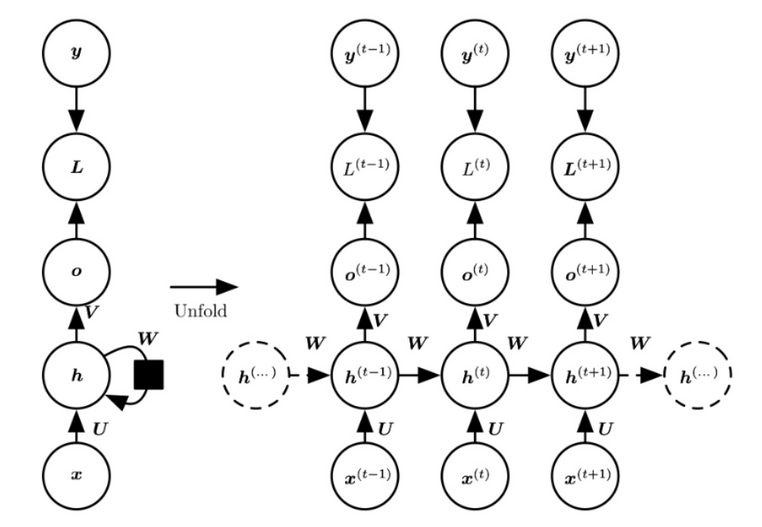
关于每一个时间步是 Y_hat 不继续传导到下一个时间步的推断。举个例子,如果要预测“我爱你中国”,已经输入单词是“我爱”,那么这个时候第三轮时间步推断出是“你”还是“他”这件事情,并不带入到下一个时间步,但是“如何推断出” —— 这件事,会传导到下一个时间步,其实也就是 A(t-1)。这样对于 A(t-1) 这个矩阵理解起来会更形象。
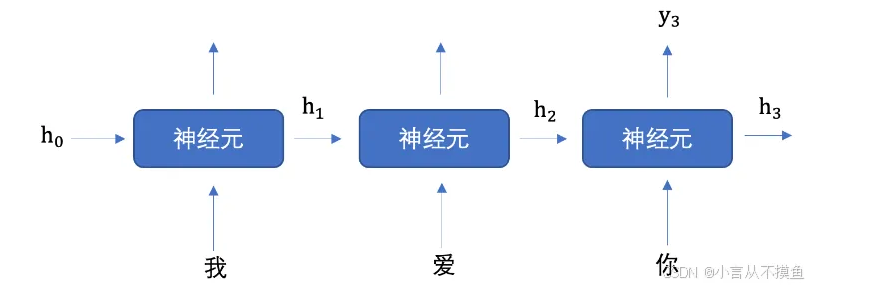
8.3.2 循环神经网络 dropout 没懂
8.4.2 时间序列预测 没懂
第八章 自然语言建模
以下是书上原话。
简单地说,语言模型的目的是为了计算一个句子出现概率。在这里把句子看成是单词的序列,于是语言模型需要计算的就是 P(w1, w2, ... ,wm)。那么,针对 m 个单词的句子,其概率公式可以这么表示:
p(S) = p(w1, w2, ... ,wm) = p(w1)p(w2 | w1)p(w3 | w1, w2) ... p(wm | w1, w2, ... ,wm)
为了估计这些参数的取值,常见的方法有 n-gram 方法、决策树、最大熵模型、条件随机场、神经网络语言模型,等等。本节将以其中最简单的 n-gram 模型来介绍语言模型问题以及评价模型优劣的标准。这里不赘述。
p(w_i | w_i-n+1, ... ,w_i-1) = C(w_i-n+1, ... ,w_i-1, w_i) / C(w_i-n+1, ... ,w_i-1)
C(X) 表示单词序列 X 在训练语料中出现的次数。另外,再学习一个评价模型好坏的指标。
语言模型的效果的好坏常用评价指标是复杂度 Perplexity,通过语言模型计算得到的这句话的概率越高越好,也就是 Perplexity 越小越好。事实上,复杂度 Perplexity 表示的概念,其实是平均分支系数 Average Branch Factor,即模型预测下一个单词时候的平均可选择数量。因此,如果一个语言模型的 Perplexity 是 89,表示平均情况下,模型预测下一个单词时候,有 89 个单词等可能地作为下一个单词的合理选择。公式大家可以查阅《TensorFlow 实战 Google 深度学习框架》。
第八章 长短时记忆网络 LSTM
书上原话。
循环神经网络工作关键点就是使用历史的信息来帮助当前的决策。例如使用之前出现的单词来加强对当前文字的理解。循环神经网络产生更大的技术挑战,即长期依赖 Long-term dependencies。例如,“大海是蓝色的”最后一个单词“蓝色”,无需进行长期记忆和学习。然而,要判断的句子是长难句,又含有转折的时候,又会产生什么效果呢?例如,现在理解“某地设置了大量工厂,空气污染十分严重 …… 这里的天空都是灰色的”最后一个单词也是颜色,应该是“蓝色”呢?还是“灰色”呢?
依据人类的思考习惯,是先要知道前文的意思,依据连接词的意思进行推断。换言之,如果要让计算机分析这句话,得让计算机“知道为什么”。书上原文:“最后一个词可以是‘蓝色’或者‘灰色’。但如果模型需要预测清楚具体是什么颜色,就需要考虑先前提到但离当前位置较远的上下文信息”。“预测位置和相关信息之间的文本间隔就有可能变得很大。当这个间隔不断增大时,简单循环神经网络有可能会丧失学习到距离如此远的信息的能力”。为了解决这个问题,长短时记忆网络 LSTM 应运而生。
很多任务上,采用 LSTM 结构的循环神经网络比标准的循环神经网络表现更好。算法提出于 1997 年,LSTM 是一种拥有三个“门”结构的特殊网络结构。LSTM 结构的核心,“遗忘门”。
“遗忘门”和“输入门”至关重要,它们是 LSTM 结构的核心。“遗忘门”的作用是让循环 神经网络“忘记”之前没有用的信息。比如一段文章中先介绍了某地原来是绿水蓝天,但后来被污染了。ShoelessCai 评注,这里有个“但是”,因此需要“遗忘门”来忘记一些让步条件,得到真正的结论。
于是在看到被污染了之后,循环神经网络应该“忘记”之前绿水蓝天的状态,这个工作是通过“遗忘门”来完成。“遗忘门”会根据当前的输入 x(t)、上一时刻状态 c(t-1) 混合上一时刻输出 h(t-1) 共同决定哪一部分记忆需要被遗忘。在循环神经网络“忘记”了部分之前的状态后,它还需要从当前的输入补充最新的记忆。
这个过程就是“输入门”完成的。“输入门”会根据 x(t)、c(t-1)、h(t-1) 决定哪些部分将进入当前时刻的状态 c(t)。比如,当看到文章中提到环境被污染之后,模型需要将这个信息写入新的状态。通过“遗忘门”和“输入门”,LSTM 结构可以更加有效地决定哪些信息应该被遗忘,哪些信息应该得到保留。
ShoelessCai 收集的网上资料。
其实,之前学习的循环神经网络有一定的局限性,例如,梯度消失、梯度爆炸、长期的信息依赖问题,第三个问题和含义是,RNN 难以捕捉序列中相隔较远的依赖关系。为了解决这些问题,提出长短时记忆网络,被广泛用于许多序列学习任务,例如语音识别、机器翻译、时间序列分析等等。
那么,如何来表示所谓的“遗忘门”、“输出门”呢?
首先,每层网络都计算一个遗忘因子
f(t) = A( w(f) · [h(t-1), x(t)] + b(f) )
其中,A() 是激活函数,w(f) 权重矩阵,h(t-1) 上一层的 A(),x(t) 新的输入,b(f) 截距。
那么,短期要保留是否存爱记忆性?要找出来吗?答案是肯定的。关于保留的信息 i(t),以及保留的信息矩阵 C(t) 有以下关系。
i(t) = A( w(t) · [h(t-1), x(t)] + b(i) )
C(t) = tanh( w(c) · [h(t-1), x(t)] + b(c) )
不难发现,保留信息的系数,其计算方式和遗忘信息的系数的计算方式很类似。而具体的保留的信息,需要 tanh() 这个激活函数再次激活一次。那么每层神经网络,如何确定,遗忘哪些信息?保留哪些信息呢?
C(t) = f(t) * C(t-1) + i(t) * C_hat(t)
确定每层网络的信息集合 C(t),计算输出门的公式。
o(t) = A( w(o) · [h(t-1), x(t)] + b(o) )
h(t) = o(t) * tanh( C(t) )
Needless to say,C(t) 含义是 Cell Information。
参考文献
[1] deephub(2021),可视化特征图,知乎,2021
[2] rdcamelot(2025),循环神经网络,博客园,2025
[3] aliyun4137863809(2024),深度学习入门:循环神经网络 —— RNN概述,词嵌入层,循环网络层及案例实践!(万字详解!),阿里云,2024
[4] 卡伊德(2022),循环神经网络(RNN)详解-计算公式推导,腾讯云,2022
[5] 千里马不常有(2024),时间序列预测:基于PyTorch框架的循环神经网络(RNN)实现销量预测,CSDN,2024
[6] windwant(2025),循环神经网络(RNN):时序建模的核心引擎与演进之路,CSDN,2025
[7] 凌逆战(2019),循环神经网络(RNN)及衍生LSTM、GRU详解,博客园,2019
[8] 韦伟(2020),史上最详细循环神经网络讲解(RNN/LSTM/GRU),知乎,2020