再次精读 SVM SMO 代码
为了加深理解,写完之后我还朗读了一遍。
今天要讲解 SVM,此前解读过一遍,但是考虑到这个“超平面”怎么回归出来的,还是一脸懵,那就说明没学懂,因此,这次得空,再讲解一遍。平时使用的时候,是调用 python sklearn 的计算包,也不纠结内部的算法。一种算法,很可能也是很多人使用的方法,就是先用随机选择几个点(也可能是所有的点)回归出一套系数,这套系数肯定效果不怎样,但是,我们懂得目标函数、约束,还有迭代算法,这些知识有什么用呢?这些知识可以帮助我们,在有个很不咋地的“解”,能够不断迭代这个“解”,使得它不断收敛到这个问题最优的解。这种做法,我们称为“运筹算法”,现在人们都称作“机器学习”,应该属于机器学习一部分。因运筹主要解决线性问题,那么,机器学习涉及很多非线性算法。
注意,上述这段思路很可能是错的!本文最后揭晓目前最流行的算法是什么!
第一步,了解 SVM 原问题,最小化权重向量的模长的和。
第二步,发现原问题难以求解。至今,SVM 使用的仍然是线性的解法。这种线性解法怎么求解呢?线性规划中求解原问题的一个做法,就是求解对偶问题。直观地理解,可以理解为“原命题”和“逆否命题”,有时候“原命题”难以证明,转向证明“逆否命题”比较容易,那么我们就会致力于证明逆否命题。SVM,在真正求解过程中,求解的是其对偶问题。
第三步,对偶表达式和约束条件如下。
第四步,这个问题怎么求解呢?这里要引入 SMO(Sequential Minimal Optimization),即“序列最小优化算法”。
第五步,简要地用文字表述,如果读者想要知道算法具体运作,就必须读懂代码。关于算法,有 3 个参数是需要迭代的,即对偶问题中的权重 alpha 以及截距 b,还有用于判断算法停止的误差项 Error,用 Ei 表示。这三个参数在算法行进的过程中,不断迭代的。初始均为 0。
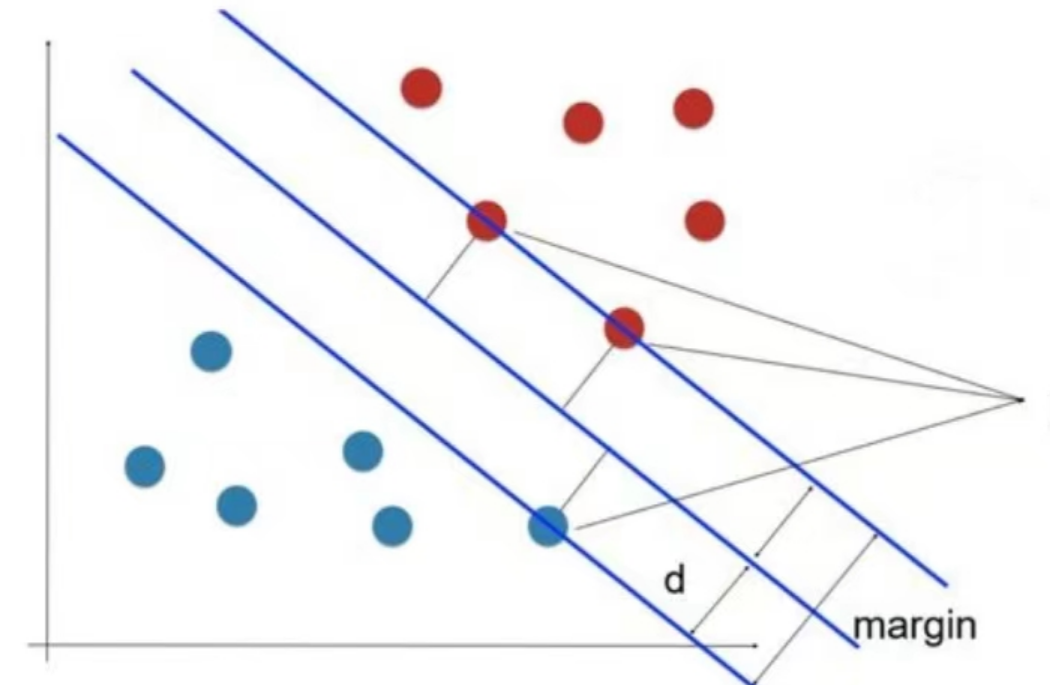
第六步,算法停止条件是什么?算法会一次搜索所有的样本点,保证这些“向量”满足条件(通常称为KKT条件),计算机中“满足条件”怎么衡量?其实,每个样本都存在一个误差 Ei,所谓满足条件,即 Ei 和 Ej 之间的距离,小于一定的值。例如,|Ei - Ej| < 0.0001。
第七步,现在来理解,搜索是怎么搜索的?这是 SMO 的精髓。
(1)找到背离 KKT 条件最远的点,称为 alpha(i)。这是外层循环,每个循环轮次,就是找到背离 KKT条件最远的点;
(2)内层循环,集合1是支持向量集合,集合2是整个样本集合。集合1每个样本点都有对应的误差项 Ej,内循环的时候,要在上述这个集合1里,找到一个样本,使得 |Ei - Ej| 之间的距离最大。如果,这个样本点找不到的话,就在集合2中搜索,通常搜索集合2的时候,还需要现场(在循环内)立即算出一个误差项 Ej。如果上述搜索原则,能找到第二个样本点,那这两个样本点,就能够求出若干组向量,分别迭代权重 alpha,截距 b,以及误差向量 E,也就是第五步中所说的 3 个参数。
(3)外层循环每运行一次,集合1里的元素就会增加。设计的时候,内层起作用为1,没起作用就为0。本篇解释的代码(可能有其他做法),只要迭代到指定次数就停止。观点,原作者这么处理是不影响对算法的理解的。因支持向量集合,即集合1肯定是非空。每完成一个外层循环,其样本点一定是非零的,支持向量集合一定非空。此时,就完成对算法的理解。
(4)实际应用时候。一种做法,搜索样本集合中所有的点,使其满足一定条件;另一种做法,是规定住迭代的轮次。两种做法都行,取决于自己的应用。
未完待续,慢点补上代码解读。
使用 cvx 工具箱求解 svm svm 模型 ML小白推导SVM决策超平面求解过程 支持向量机原理详解(七) SMO算法精解 保姆级笔记-详细剖析SMO算法中的知识点
代码地址,这是知乎上大神写的。点击
查看代码 。
本篇代码一共 7 个函数。
1.kernel_ij( X, i, j, kernel )
2.kernel_mat( X, xi, i, kernel )
3.cal_error_i( self, X, y, i )
4.update_params( self, X, y, i, j, Ei, Ej )
5.inner_alpha( self, X, y, i )
6.smo( self, X, y )
7.fit( self, X, y )
其中,
kernel_ij() 输出第 i 个向量,和第 j 个向量的核。最简单的是线性和,只需要做线性组合。输出一个数值 kij
kernel_mat() 以样本量 N 为循环次数进行循环,输出一组向量 [k11, k12, ...]
cal_error_i() 输出数值。一个样本一个 error。
update_params() 更新三个向量,即权重 alpha,截距 b,以及对应样本的误差向量 E。原文用 class() 完成更新和保存。
inner_alpha() 直接修改在 class() 上,开启内循环,如果内层循环找到某个样本点 ,返回1,内层循环没有找到某个样本点,返回0。内层循环的判断标准。什么叫做找到合适的 alpha(j) 呢?即 |Ei - Ej| 达到最大。
smo() 这个是作者自己写的规则,停止条件是循环次数。外层找到背离 KKT 最多的 alpha。内层,先搜索支持向量集合,要是都不满足要求,则搜索整个样本集合。
介绍完 SMO 最小序列优化算法之后,我们来回顾自己的“直觉”和“想象”,即一开始生成一套系数,再用优化算法迭代诸轮次,每个轮次我都计算目标函数,是否可行。在查看源代码之后发现,所谓的“先回归一个模型,再迭代”的做法并不存在,目前熟练用的 Package,使用的就是 SMO 算法。当然,我们也可以这样考虑这个问题不妨动手做做实验,看看 SMO 和迭代提升模型的做法,哪个速度更快!这也是学算法的人的追求吧!
这是在网上找到的 SVR 源代码。
点击阅读 。关键在于源代码的停止原则也是 iter > max_iter!