前段时间重操旧业,开展建模工作。建模这件事情,完全自己独立完成也行,但是工作的意义就在于,你在某个地方卡住或者出现谬误的时候,队友可以出现,做一些修正和启发的工作。当然,拥有一个建模群是比较有好处的,但是,大概也只有在做一些直接关乎收益的模型时,人们才会绞尽脑汁思考问题出在哪里。
介绍一下建模的大致思路,代码和细节得读者自己发展。
01 知道你的主键
首先,基础数据方面,提交的最终数据集就三个关键字段,即用户ID、商户ID,以及用户在某商户购物的概率。用户行为数据,包含几个关键的唯一编码,即用户编码、商品编码、商品类别编码、商户编码、商品品牌编码、购买时间、动作标识(包括单击、添加到购物车、购买、收藏到文件夹)。用户画像,用户编码、年龄、性别。
数据处理阶段,使用python之后会有些偷懒,通常都是fillna(-1) 解决,缺失值也可以用-999,-9999替代,取决于数据取值分布。之前处理缺失,功能不复杂自己写函数,如果缺失没有业务差异,可以不区分。该阶段对于数据表认知很重要,需要对数据存储方式、如何触发具有较深刻的理解,这样可以保证拼宽表比较有效率,而且不容易出错,这里的关键字段是时间戳。
02 理解你的业务
其次,是特征工程,这部分很关乎对业务的理解,要善于利用数据的信息,识别出数据微妙的变化。这部分建模人员的数据分析能力、对数据的理解能力、对业务的理解能力,都显示在自己做的特征变量里,某种程度也增加建模拟合最佳的上限。但是,笔者也看过一些技术流,比较不同特征工程对模型的作用,得出真正拓展上限的其实也不在特征。
数据集分割。这步很关键却很容易被忽略,因为几乎只有在发现模型实际使用效果不好的情况下,才知道数据集分割可能不合适。因此,该步骤笔者采用稳妥策略,即在特征工程之前,就先留出一部分数据集,称作“完全留出验证集”,用于评价评分好坏。因为完全留出验证集合不参与特征选择,对于模型特征的泛化能力、模型预测能力,都具有非常有说服力的检测效果。
03 特征选择 - IV值
再者,是特征选择。部分团队和笔者交流过,会大面积形成特征计算和留存,虽然没有计算过占用的资源,但似乎是很多技术流偏好的方式。但是,作为数据流不是很能理解,如何利用这样的基础设施建设,也许可以再推出一些天河大赛、天辣大赛之类的。最近看《阿里云天池大赛赛题解析》,提到特征的数量会影响算法的表现,变量的数据形态、过度拟合都会影响最终效果,总之进入模型的特征数量仍然是有一个经验值。
特征选择,笔者前同事付同学提出一种迭代法,业界也有不少人用,也可以亦步亦趋地选变量集合,就是所称的stepwise,选一个特征判断一遍,剔除一个特征再判断一遍。笔者偏好有内在逻辑基础的分类及人工选,有内在逻辑佐证,通常比较能保证效果。之后笔者也会思索自动化这种模式,即用K-Nearest对变量进行分类,分类的标准有多种可选,例如Pearson Co-efficient,欧式距离,笔者用的欧式距离,被归为一类的称为“簇”,每个簇中选取IV值最大的特征。如果不想选特征,就直接简单粗暴地用bagging算法,算法和速度其实都不输boosting。
特征选择阶段,部分建模人员会选择剔除一些特征。基于审慎考虑,笔者很少在这阶段剔除特征,除非全部缺失,或者全部无效值。建模也像练武,一偷懒,功夫就练不成。
特征选择的标准,目前笔者仍然使用IV(Information Value)的方式,也可以使用算法内部衡量标准,metric比较多,MSE、AUC、Accuracy都是选择。采用哪种方式和标准,取决于建模人员的价值取向。
04 参数调整
第四步是调整参数。部分同学会先调整hyperparameter,我对此理解是类似于迭代次数这种独立于模型参数之外,决定模型跑多少,跑到什么程度的参数。笔者简单粗暴地,罗列出模型内部和外部参数,以线性序列一个一个调。也考虑过Grid Search,但是遵循乘法原则的Grid Search,其迭代次数是所有参数向量维度的乘积,我目测一下,计算量实在太大,还是用的线性序列。如果有同学对于,为什么线性序列和Grid Search差距不会太大感兴趣的话,也可以和笔者聊聊。
参数调整过程中,为了增加模型的稳定性,无论是为了自己心里有谱,还是为了可以说服客户,都是用的K折交叉验证,通常都用3折、5折、10折交叉验证。简单来说,数据集分成10份,9份用于训练,对于参数的估计theta_hat,是在训练数据集之外的1/10数据上的预测,这种做法可以保证,估计参数theta_hat并非用训练集预测。
05 交叉验证,提升模型可信度
经验上来说,数据量达到千万级别的模型用10折交叉验证,需要调整的参数数量稍微多几个的时候,建模人员会被公司判断为工作量不饱和、上班偷懒等情况。因此3折、5折也能达到效果。有读者对于为什么能够这样做、为什么能够有自信这样做感兴趣的,也欢迎多关注ShoelessCai。
最后一步是检验。这一步最困难,因为其他建模人员总是用AUC、MSE轻松搪塞掉。然而,遇到数据集合分布较偏,目标样本较少,AUC怎么调都是0.5附近一如没有模型一般。加上许多公司业务目标也不一致,衡量标准具有比较大的发挥空间。
形如XGBoost、LightBGM都可以用于评分卡,作为一种叠加模型使用。折算成评分的好处在于,可以忽略掉模型的数学因素,从模型使用的角度理解数学模型。
06 适当使用 BootStrap
在数据量不大的时候,可以采用Bootstrap方法,建立模型序列,考察每个评分区间的Hit Rate分布,笔者通常以众数作为最终选择。
笔者用上述流程测试过两个数据集,数据集合在几十万、几千万不等,能够获得的Hit Rate,在评分顶部获得的Hit Rate介于30%-40%。以获取信用风险的坏客户为例,评分顶部(尾部)某个cutoff区间内的客户,有40%预期未来会违约的。
文章的尾端,介绍样本较偏情况下的解决方案。
- 第一,可以依据业务情况,适当减少表现期长度,以金融模型为例。金融模型需要较好的泛化能力,尽量减少misclassification的概率,因此表现期较长,至少是以年为单位的。但是,民间的资本借贷业务大多达不到上述成熟期的标准,受制于业务本身限制,减少表现期可以增加好坏比例。
- 第二,SMOTE,样本均衡。笔者做SMOTE比较简单粗暴,采用的是线性组合模拟新样本。会考虑具有明显差别的因素,在生成模拟样本的时候,对其权重进行调整。
- 第三,算法包内相关样本权重参数。例如,XGBoost就有相应参数可以调整,这部分笔者作为调整的参数向量的一种,其作用尚未核实。其他算法也有对样本不均衡时候的处理方式,而且,虽然不知道为什么,那些搞模型的面试,特别喜欢问,你知道某个参数吗?——这类问题。作为一个工作5年升职很困难的人,我真的觉得有点初级。
- 第四,如果对数据集真的没信心,也可以考虑Bootstrap,证明本篇就忽略了。
接下来,看看笔者测试的天猫复购率模型,选取部分步骤,但求切中要害,游刃有余。
1. 数据集简介
经典赛题,读者自行下载数据。
2. 参数调整过程
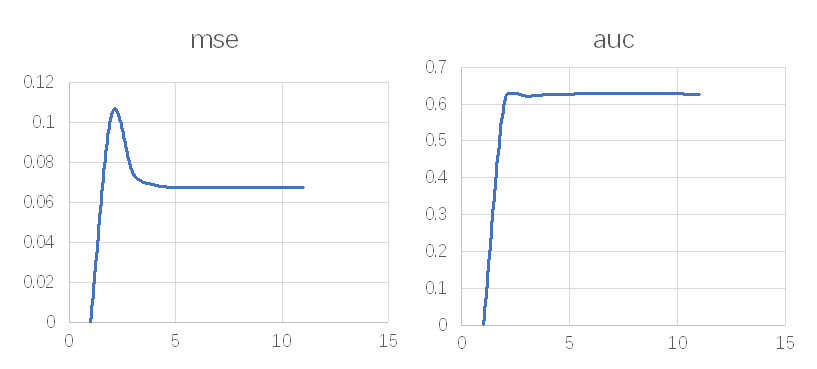
笔者选取学习率参数的调整,不同算法包的名称有差异。查看的监控指标是均方误MSE和区分力指标AUC,下述曲线走势比较理想,便于建模人员确定合适的值。定阈值具有主观性,通常最大或最小值,或者突然趋势变化的点,有称作Elbow,或者尖刺,或者凹凸变化的点(比较少见)。
3. Bootstrap 确定参数
这种操作,主要还是因为到笔者手里的数据,除了第一个信用卡数据集,之后都是样本特少、分布特偏的。人就是这种动物,任务越难,创新越多,但是很好用,有理论支持,能说服客户,更能说服自己。
笔者用天猫复购率数据集测试了一下,最后在确定Hit Rate的时候,采用的是评分法验证,即对所有样本打分、排序,总共分出40个Bin,查看评分顶部Bin的Hit Rate。图为第5和第38号Bin,称为Chart-5和Chart-38。其中,Chart-5的命中率主要集中在0%,而Chart-38的命中率集中在30%。这种验证方式,使得模型使用变得更加直观。

……(省略几十个Chart)

欢迎关注ShoelessCai,致力于“商业赋能行业”。